이 포스팅은 Computer Vision 시리즈 17 편 중 1 번째 글 입니다.
목차
Descripter
이미지를 비교하기 위해 동일한 방법을 통해 하나의 비교 대상으로 만드는 것
 descripter
descripter
두 가지 이미지가 있다. 이 두가지 이미지가 비슷한지 아닌지를 구분하기 위해 만든 것이 descripter이다. 위의 그림에서는 픽셀의 값들을 기반으로 gradients를 구해 이를 grid에 plot하여 표현하였다. 여기서 이 gradients를 descripter로 사용했다고 말한다.
 HOG algorithm
HOG algorithm
예를 들어 HOG 알고리즘은 각 pixel에서 gradient를 구하고 이 값들을 총 8가지 방향으로 매핑한 후, 히스토그램을 생성한다. 이렇게 추출돈 Feature vector는 keypoint이고 이를 기반으로 bounding box등을 만드는데 활용한다. 요즘은 이 feature mapCNN을 통해 생성한다.
Region Proposal
이미지로부터 영역을 선택하기 위해 사용되는 알고리즘
기존의 sliding window방식은 매우 비효율적이었고, 이를 개선한 방법이다. “물체가 있을 법한” 영역을 빠른 속도로 찾아내는 알고리즘이다. 보편적으로 selective search, edge box algorithm이 있다. 하지만 이 역시도 추후에 end-to-end 방식으로 개선된다.
RoI(Region of Interest)
이미지내에서의 관심 영역
원래 input에서 잘라낸 관심 영역들을 RoI라 한다.
Caption generation
이미지로 부터 문장을 생성하는 것
이 연구는 Human-object interaction에 기초하여 연구되고 있다.
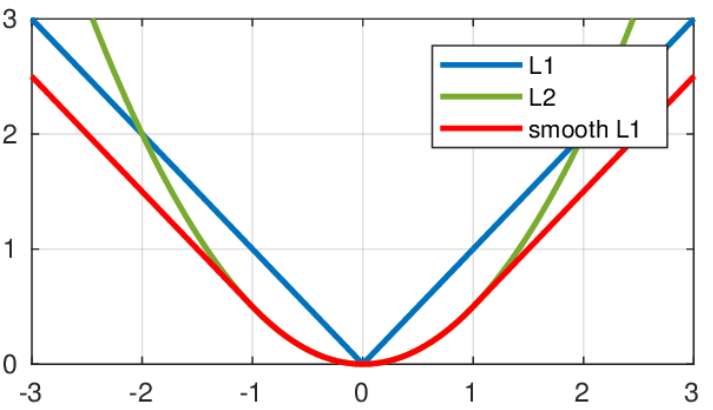
Smooth L1 Loss
\[smooth_{L_1}(x) = \begin{cases} 0.5x^2 & \mbox {if }\left| x \right| < 1 \mbox{ is even} \\ \left| x \right|-0.5 & otherwise \end{cases}\]L1, L2 Loss는 생략하였다. 수식에서의 x는 $|y-\hat{y}|$로 정답 label과 차이이다. 오차가 작은 부분은 제곱을 사용했고, 그렇지 않은 부분에서는 직선을 사용했다. 이러한 방식은 L1 Loss와 L2 Loss의 장점을 결합한 형태이다. 즉, error가 클경우 안정적으로 loss를 감소시키고($x$)
, 작을 경우에는 L2 Loss를 사용하여 업데이트 과정중 진동을 감소시킨다.
IOU (Intersection over union)
예측한 bounding box와 ground truth box간의 겹치는 넓이 비율
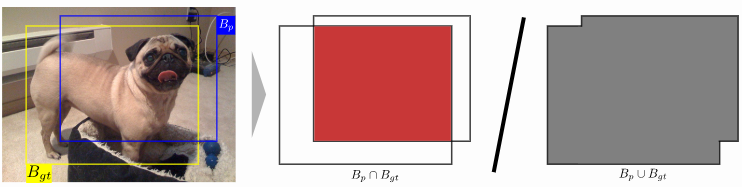 IOU
IOU
이것은 사진으로 직관적으로 이해할 수 있다.
Ablation study
기존 모델에서 feature를 제거하면서 영향력을 확인하는 것
여기서 feature는 변수보다는 network, layer등을 말한다.
Jittered examples
IoU를 기준으로 사용하겠다고 판단한 bounding box
bounding box regression을 진행한 후에 각각의 proposal에 대해 예측한 결과 중 학습에 재사용하기 위한 샘플을 걸러낼 때 사용되는 개념이다. 예를 들어 IoU가 0.5이상 인 샘플을 positive sample이라 정의할 경우, 이 샘플을 Jittered examples이라 한다.
Non-maximum suppression (NMS)
동일한 클래스라 판명된 bounding box들 중 중복을 제거하는 방법
 Non-maximum suppression (NMS)
Non-maximum suppression (NMS)
알고리즘은 다음과 같다.
- 동일한 클래스에 대해 검출된 bounding box들을 confidence 순서로 정렬한다.
- 가장 confidence가 높은 bounding box와 IoU가 일정 이상인 bounding box는 동일 물체를 detect했다 판단하여 지운다.
- 가장 confidence높은것만 남기고 보통 0.5이상 box들을 지운다.
OHEM (Online Hard Example Mining)
먼저, Hard Example과 Easy Example의 개념부터 알아보자. 사람인지 아닌지를 분류하는 모델이 있다고 하자. 우리의 목적은 이 모델을 훈련시키는 것이다. 대부분의 사람 이미지는 분류하도록 만들었다. 하지만 사람 동상과 같은 샘플에 대해서는 모델이 구분하기 어려울 것이다. 이러한 상황에서 일반적으로 잘 동작하는 샘플을 Easy Example, 사람 동상 이미지를 Hard Example 이라 한다. 이런 것들을 제대로 훈련하기 위해서는 Hard Example에 대해 가중치를 주거나 해서 모델을 훈련시켜야 할 것이다.
다음은 positive와 negative에 대한 개념이다. positive는 문제에서 내가 원하는 클래스를 의미한다. positive sample은 bounding box의 label이 사람인 것을 의미하고, negative sample은 배경임을 의미한다.
그렇다면 hard negative란, 실제로는 배경인데, 사람이라고 예측한 sample이다. 반대로 easy negative는 실제로 배경이며 배경으로 예측했음을 의미한다.
즉, hard negative sample은, 네거티브 샘플이라고 보기 어렵다라는 의미이다. 해당 샘플에 대해 배경이라고 말해야 하는데, confidence는 높게 나오는 상황을 말한다.
우리가 알아볼 object detection문제에서는 resion proposal을 통해 여러가지 후보를 선택하게 된다. 이 후보군의 대부분은 배경이라고 말해야 하는 easy negative sample이 차지하고 있다. 또한 사람이라고 말해야 하는 positive sample의 개수는 매우 부족하다. 보통 이러한 상황에서는 모집단의 balance를 맞추는 resampling을 진행하거나, boosting알고리즘으로 진행하게 된다. 하지만 이것은 label의 불균형을 알고있고, 이를 처리할 수 있을 때 가능하다. detection문제는 후보군의 label을 모르기 때문에 이 방법은 사용할 수 없다. 그렇다면 만약 이 상황에서 그대로 훈련을 진행하게 되면, easy negative sample의 양이 너무 많기 때문에 배경을 배경이라 하는 예측만이 대다수를 이루고, 이에 대해서만 학습을 진행하게 된다.
 Cross Entropy & Binary Cross Entropy
Cross Entropy & Binary Cross Entropy
일반적으로 Classification에서 사용하는 Loss 함수는 Cross Entropy 이다. 이러한 imbalance를 고려하여 업데이트를 하지 않기 때문에, 기존의 방식을 사용할 경우, background만 잘 맞추는 요상한 모델이 결과로 도출된다.
 OHEM (Online Hard Example Mining)
OHEM (Online Hard Example Mining)
우리는 결과적으로 배경은 배경이라하고, 사람은 사람이라고 하는 좋은 모델을 제작해야 한다. 그러기 위해서는 후보군의 대부분을 차지하고 있는 easy negative sample에 대해서 업데이트는 줄이고, 배경인데 배경이 아니라고 하는 hard negative sample에 대해 주된 업데이트를 진행해야 한다. 이를 위해 제안된 방법이 OHEM (Online Hard Example Mining)이다. 결과적으로 positive sample과 hard negative sample을 가지고 문제를 해결한다. 이와 같은 불균형 문제를 Class Imbalance라 한다.
Focal Loss
위의 OHEM과 비슷하게 class Imbalance를 해결하기 위한 방법이다. loss function을 수정하여 이를 해결한다.
이런 loss funtion을 이해하는 가장 좋은 방법은 양 극단치를 넣어보는 것이다. y=1일 경우, ground truth가 사람인 경우에는 해당 class가 나올 확률을 그대로 넣어준다. 즉 $p_t = p$ 이다. 그렇다면 만약 잘 맞췄을 경우에는 loss가 0에 가까워진다. 결과적으로 postitive에 대해 잘 예측할 경우 loss를 작게 주고, 그렇지 않은 경우 loss를 크게 준다.
y!=1인 경우, $p_t = 1-p$이고, 그렇게 될 경우 $FL(p_t) = -p\gamma log(1-p)$이다. cross entropy식에서 앞항과 뒤 항의 변형을 통해 log함수가 가지는 특징을 사용했다. 잘 예측할 경우 loss를 크게 주고, 그렇지 않을 경우 loss를 작게준다. 다만 log 함수에 엮여 있는 부분은 잘 예측했을 경우에 더 큰 loss값을 주게 되므로, 이 식의 의도는, 너무 잘 예측하는 데이터(p가 계속 너무 높게 나옴)의 영향력을 줄이기 위한 것이 강하다. 실제로 OHEM 보다 성능이 더 좋다고 한다.
Contextual feature
2d image에서 contextual based classification은 pixel의 주변 neighborhood 과의 relationship에 초점을 맞춘 approach를 뜻한다. 즉, 어떤 특정 pixel의 contextual feature는 주변 pixel들과의 relationship에 기반해서 추출한 feature를 뜻한다.