이 포스팅은 Computer Vision 시리즈 17 편 중 2 번째 글 입니다.
목차
Computer Vision의 Task
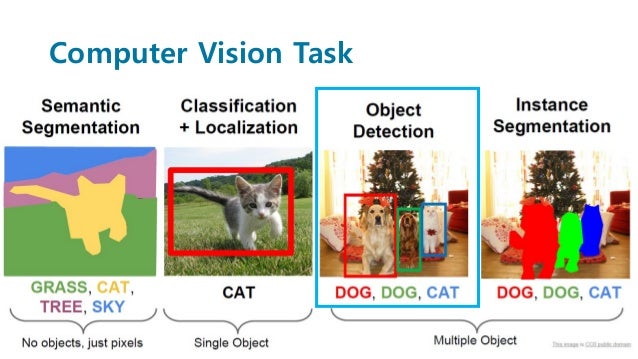 이중 Object Detection에 해당하는 문제이다.
이중 Object Detection에 해당하는 문제이다.
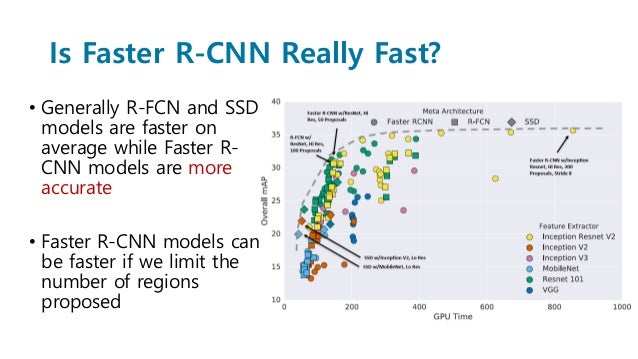 속도가 느려보여도 정확도 측면에서 높은 것을 알 수 있다.
속도가 느려보여도 정확도 측면에서 높은 것을 알 수 있다.
R-CNN
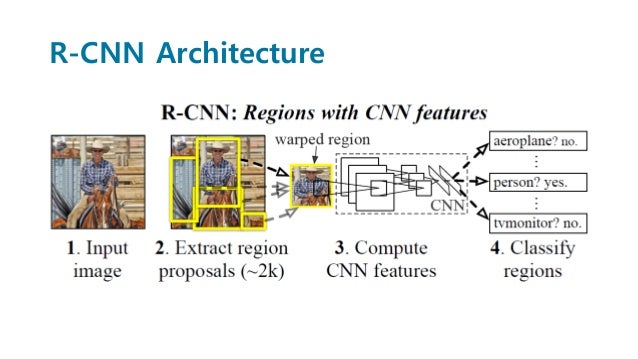
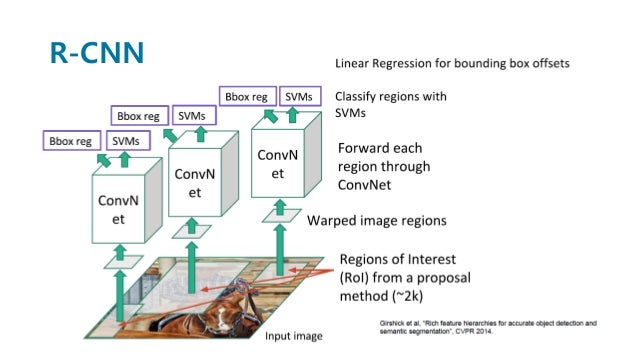
- region proposal을 진행한다.
- CNN에 각각 넣는다. -> 느리다, CNN을 사용하기 때문에 입력 크기가 동일해야 한다.(warpping)
- CNN의 마지막 feature map에서 SVM을 사용하여 구분한다.
- 또한 입력으로 주어진 bounding box를 조정하기 위해 regression을 진행한다.
Region Proposal
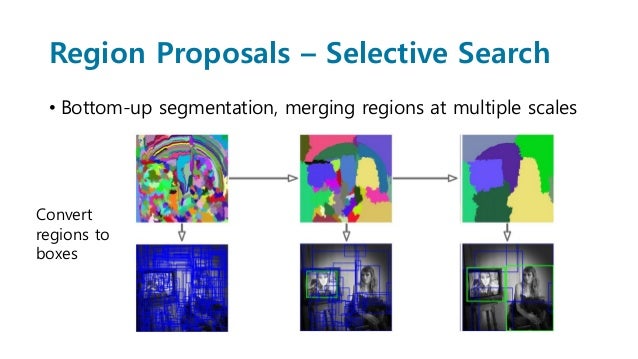
initial bounding box를 selective search를 사용하여 뽑아낸다. -> 느리다.
Training
- pretrained model = alexnet for ImageNet classification dataset
- 이미지넷에서 사전 훈련된 알렉스 넷을 사용했다. 마지막단을 잘라서 사용한다.
- 가지고 있는 데이터를 넣어서 훈련한다.
- 여기서 발생한 마지막 feature map을 가지고 와서 classification, bounding box regression 을 진행한다.
이러한 방법은, 두가지 문제를 발생시킨다.
- 속도
- 마지막 단의 feature map을 사용하기 때문에 back propagation을 통한 학습이 불가하다.
Bounding-Box Regression
Box는 centerX, centerY, Width, Height로 표현된다.
\[P^i = (P^i_x, P^i_y, P^i_w, P^i_h) \\ \\\\ G = (G_x, G_y, G_w, G_h)\]우리의 목적은 $P^i$ 박스를 최대한 G에 가깝게 이동시키는 함수를 학습시키는 것이다. 이를 표현해보면 다음과 같다.
\[d_x(P), d_y(P), d_w(P), d_h(P)\]x, y의 경우는 평행이동이 연산의 전부이기 때문에 linear 연산으로 처리가 가능하다. 반면 너비와 높이는 확대, 축소 변환이 필요하다. 단순한 확대 축소 연산을 사용하게 되면, 추후에 backpropagation을 통한 학습이 어려워지기 때문에 여기서는 exp를 사용했다.
\[\hat{G_x} = P_wd_x(P) + P_x \hat{G_y} = P_hd_y(P) + P_y \hat{G_w} = P_wexp(d_w(P)) \hat{G_h} = P_hexp(d_h(P))\]왜 굳이 식을 이렇게 만들었냐 보다는, 이러한 방식으로 제안을 하려고 했다고 생각해보자. P에 대한 변수는 초기에 제안하는 것이므로, 우리는 함수 $d_*(P)$ 가 어떤 녀석인지 아는 것이 목표이다. 그리고 이 함수를 알아내는 과정은 deep learning network를 사용하여 만들 것이다.
\[d_*(P) = {w}^T_*\phi_5(P)\]여기서 $\phi_5(P)$는 pretraioned model의 가장 마지막 feature map을 의미한다. 결국 feature맵에 선형 연산을 추가하여 원하는 함수를 구한다.
그렇다면, 이제는 문제가 변화했다. ground truth에서 발생하는 함수와 제안된 방법의 함수 $w^T_* \phi_5(P)$ 의 가중치 $w^T_*$ 를 구하는 문제이다.
ground truth에서 발생하는 값인 $t^i_*$는 각각의 사진 한장에 대해서 고정되어 있다. 이를 반영한 손실 함수는 다음과 같다. 저자들은 람다를 1000으로 설정하였다.
\[w_* = \underset{\hat{ w_*}}{argmin}\sum_i^N(t^i_*-{\hat{ w_*}^T}\phi_5(P))^2+\lambda \lVert {\hat{ w_*}^T} \rVert ^2\]한계
- 느리다.
- SVM은 CNN을 훈련시키지 못한다.
- Multostage Training Pipeline이다.
Reference
PR-012: Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Networks