이 포스팅은 Computer Vision 시리즈 17 편 중 6 번째 글 입니다.
목차
Task
Segmentation
 Types of Task
Types of Task
semantic segmentation은 이미지 내에 있는 물체들을 의미 있는 단위로 분할해내는 것이다. 좀 더 구체적으로 이야기하면, 이미지의 각 픽셀이 어느 클래스에 속하는지 예측하는 것이다. 이렇게 이미지 내 모든 픽셀에 대해서 예측을 진행하기 때문에 이 과제를 dense prediction이라고 부르기도 한다. 어떤 이미지 내에는 사람, 자동차, 강아지, 고양이, 노트북, 선풍기 등 여러 종류의 물체가 포함되어 있을 수 있다. 이렇게 서로 다른 종류의 물체들을 깔끔하게 분할해내는 것이 semantic segmentation의 목적이다.
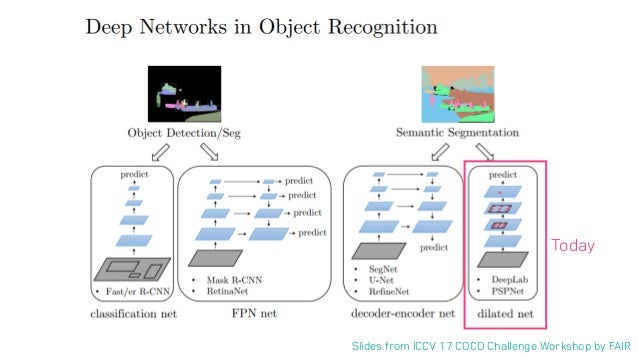 관련 논문들
관련 논문들 할거개많다
이 중에서 의미론적인 구분을 하는 Sementic Segmentation 중에서 Deep Lab에 대해 알아볼 것이다. 다음으로는 U-Net, 마지막으로 instance 단위로 segmentation을 진행하는 instance segmentation을 알아볼 것이다.
알아두어야 할 것
- 평가 metric
- IoU(intersection over Union)
- 사용 데이터셋
Fully Convolutional Networks
Fully connected 대신 Fully convolution!
- Baseline
- Fully Convolutional Networks for Semantic Segmentation”, 2014
Sematic Segmentation = Pixel level Calssification??
CNN은 image classification을 잘한다. 그렇다면 Sememtation은 pixel 단위로 classification을 진행하면 되지 않을까? 하지만 굉장히 비효율적이다. 그렇다면, 최대한 기존 network의 구조를 변경하지 않으면서 이걸 가능하게 할 방법은?
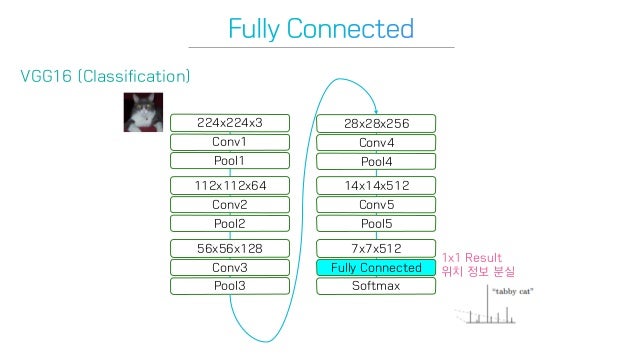
 기존 VGG16 network
기존 VGG16 network
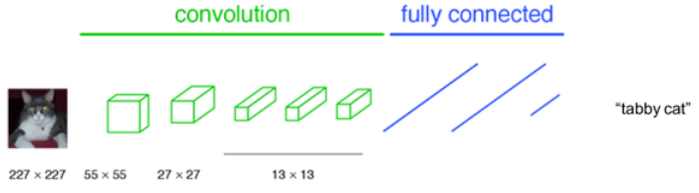
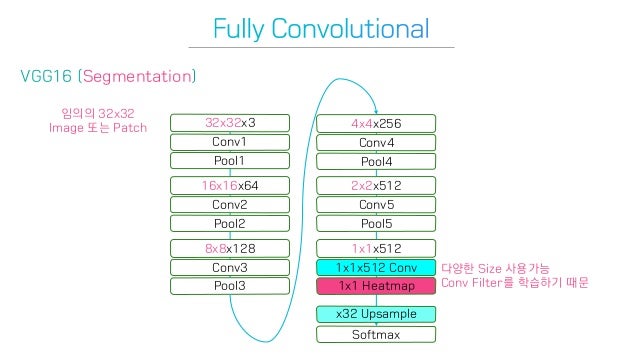
AlexNet, VGGNet 등 이미지 분류(image classification)용 CNN 알고리즘들은 일반적으로 컨볼루션 층들과 fully connected 층들로 이뤄져있다. 입력이미지에 의존도가 크기 때문에 항상 입력이미지를 네트워크에 맞는 고정된 사이즈로 작게 만들어서 입력해준다. 그러면 네트워크는 그 이미지가 속할 클래스를 예측해서 알려준다. 아래 그림에서 네트워크는 입력된 이미지의 클래스를 얼룩무늬 고양이(tabby cat)라고 예측해냈다.
이 분류용 CNN 알고리즘들은 이미지에 있는 물체가 어떤 클래스에 속하는지는 예측해낼 수 있지만, 그 물체가 어디에 존재하는지는 예측해낼 수 없다. 왜냐하면 네트워크 후반부의 fully connected 층에 들어서면서 위치정보가 소실되었기 때문이다. 따라서 AlexNet, VGGNet 등과 같은 알고리즘들을 수정함없이 Semantic segmentation 과제에 그대로 사용하는 것은 불가능하다.
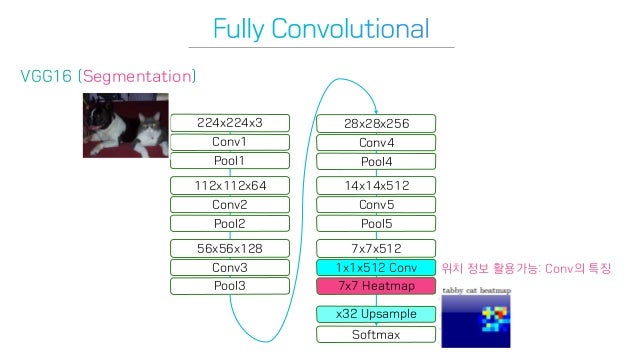
 Fully Convolutional Network
Fully Convolutional Network
그래서 저자들은 1x1 filter를 사용하여 위치정보를 살렸다. 마지막 단에는 7x7 heatmap 을 output으로 내고, 이를 원래 image size로 upsampling을 진행하여 문제를 해결하고자 하였다.
결과적으로 네트워크 전체가 컨볼루션층들로 이뤄지게 되었다. fully connected 층들이 없어졌으므로 더 이상 입력 이미지의 크기에 제한을 받지 않게 되었다.
 입력 크기에 대해 자유로워졌다.
입력 크기에 대해 자유로워졌다.
저자들은 Fully Convolutional Network는 1x1 filter를 사용하기 때문에 input image에 대한 dependency가 작은 것도 장점이라 했다. 1x1 conv는 Width, Height에 대해 의존도가 없기 때문에 channel 수를 마음대로 조정하여 원하는 output 모양을 맞출 수 있다. 여러 층의 컨볼루션층들을 거치고 나면 특성맵(feature map)의 크기가 H/32 x W/32가 되는데, 그 특성맵의 한 픽셀이 입력이미지의 32 x 32 크기를 대표한다. 즉, 입력이미지의 위치 정보를 ‘대략적으로’ 유지하고 있는 것이다.
Upsampling
feature map을 키워서 image size로 만들자!
 Heatmap과 Upsampling
Heatmap과 Upsampling
입력이미지의 위치 정보를 가지고 있는 Heapmap은 아직 대략적인 정보(Coarse)일 뿐이다. 이러한 정보를 기반으로 원래 이미지의 Pixel Size에서 class를 예측하는 dense Prediction을 수행해야 한다. 이 과정에서 Heat map을 원래 image size로 크기를 키워주는 과정을 upsampling이라 한다.
 FCN-32s 모델의 전체 과정
FCN-32s 모델의 전체 과정
하지만 단순히 upsampling을 진행하면 예상하겠지만 여전히 Coarse한 segmentation map을 얻게 된다. 단숨에 32배 한다면 coarse 할수 밖에 없다. 이렇게 단숨에 32배 upsampling한 네트워크를 FCN-32s라 소개하고 있다. 확실히 정확도가 많이 떨어진다.
 FCN-32s : Coarse Output
FCN-32s : Coarse Output
Skip Combining
이전 단계의 컨볼루션층들의 특성맵을 참고하여 upsampling을 해주자!
 FCN-16s
FCN-16s
컨볼루션과 풀링 단계로 이뤄진 이전 단계의 컨볼루션층들의 특성맵을 참고하여 upsampling을 해주면 좀 더 정확도를 높일 수 있지 않겠냐는 생각에서 Skip combining이라는 방법을 제안한다. 왜냐하면 이전 컨볼루션층들의 특성맵들이 해상도 면에서는 더 낫기 때문이다. 이렇게 바로 전 컨볼루션층의 특성맵(pool4)과 현재 층의 특성맵(conv7)을 2배 upsampling한 것을 더한다. 그 다음 그것(pool + 2x conv7)을 16배 upsampling으로 얻은 특성맵들로 segmentation map을 얻는 방법을 FCN-16s라고 부른다.
 FCN-8s
FCN-8s
또 더 나아가서 전전 컨볼루션층의 결과도 참고해서 특성맵들을 얻고, 또 그 특성맵들로 segmentation map을 구할 수도 있다. 이 방법은 FCN-8s라고 부른다. 좀 더 구체적으로 이야기하면, 먼저 전전 단계의 특성맵(pool3)과 전 단계의 특성맵(pool4)을 2배 upsampling한 것과 현 단계의 특성맵(conv7)을 4배 upsampling 한 것을 모두 더한 다음에 8배 upsampling을 수행하므로 특성맵들을 얻는다. 이것을 모두 종합해서 최종 segmentation map을 산출한다.
 skip combining의 depth에 따른 결과 비교
skip combining의 depth에 따른 결과 비교