이 포스팅은 Computer Vision 시리즈 17 편 중 12 번째 글 입니다.
목차
개요
Pretrained model을 사용하거나 Transfer Learning 을 사용하는 모델들에 대해서 읽을 때 Backbone이 되는 CNN 모델들이 몇 개 있다. VGG family, ResNet family, Inception family, 그리고 Xception. 복잡한 작업(e.g. Semantic Segmentation 등)의 기초가 되는 이 네트워크에 대해서 정리해 보자.
Xception 모델이란?
Xception 은 구글이 2017년에 발표한 모델로, 2015년에 ILSVRC 대회에서 2등을 한 Google 의 Inception-V3 모델보다 훨씬 좋은 결과를 냈다.
Encoder-Decoder 형태의 모델들에서 pretrain 된 Xception 모델이 Encoder로 자주 쓰인다. 또한 Xception 에서 제시하는 모델의 구조나 핵심인 modified depthwise separable convolution의 개념이 간단하기 때문에 다른 모델에도 적용하기 쉽다.
Xception 이라는 이름 자체가 Extreme + Inception 에서 나온 만큼 Inception 모델이 기본이 된다. 먼저 Inception 모델들에 대해서 간단하게 정리해 보자.
Inception Family
요즘에는 version 4과 ResNet이 합쳐진 Inception-ResNet v2 혼종까지 나왔다.
 Inception-ResNet v2
Inception-ResNet v2
다른 모델에 활용하기에는 복잡해서, 연산량이나 parameter의 개수가 VGG보다 훨씬 적음에도 불구하고 vgg net이 더 자주 사용된다고 한다.
차이점
보통 5x5 또는 7x7의 하나의 convolution 필터로 진행하는데, Inception 모델에서는 conv 레이어 여러 개를 한 층에서 구성하는 형태를 취하고 있다.
영화 Inception 에서 이름을 따온 이유가 여기 있다! ‘동시에’ (같은 Layer(꿈)에서) 다양한 convolution 을 진행하기 때문이다. 끼워 맞춘 것 같은거는 나만 그래?
 naive Inception module
naive Inception module
목적
딥러닝은 망이 깊을수록 (deep), 레이어가 넓을수록 (wide) 성능이 좋지만, overfitting & vanishing gradient 의 문제로 깊고 넓게만 모델을 만드는 것은 문제이다. Inception 은 Convolution 레이어를 sparse 하게 연결하면서 행렬 연산은 dense하게 처리하기 위해 고안한 모델이다.
이러한 방법을 사용하면 두가지의 이득을 얻을 수 있다.
- 파라미터 개수가 줄어든다.
- 연산량이 줄어든다.
Kernel size가 늘어날수록 연산량의 크기가 굉장히 커지기 때문에 나중에는 5x5 가 아니라 3x3을 2번 하는 방향으로 바뀐다. 더 나아가서 3x3 를 쪼개서 3x1 과 1x3 convolution 을 2번 하는 방향Asymmetric Convolution Factorizing으로 가기도 한다.
사용하는 개념
1x1 Convolution
Convolution의 연산은 [Batch Size, Width, Height, Channel], 4차원의 데이터로 표기한다. Batch Size는 이미지 뭉터기의 개수를 의미한다. 보통의 convolution 은 채널의 개수를 늘리는 방향으로 진행하지만(conv filter의 개수를 늘리는), 1x1 연산의 목적은 채널의 개수를 줄여서 압축하는데에 있다.
Residual Network(ResNet)
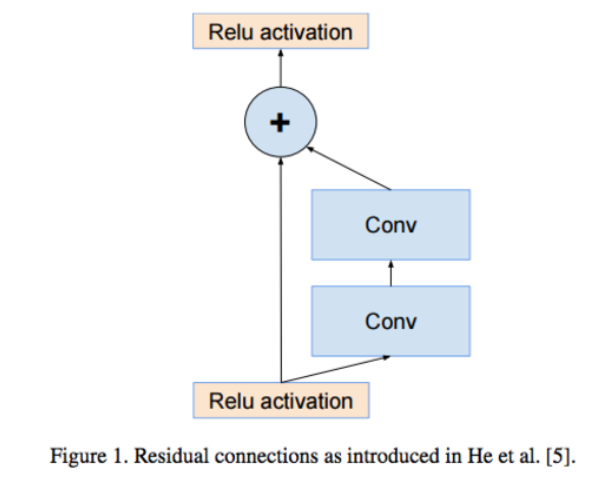 _왼쪽: 가장 간단한 형태의 residual-connection _왼쪽: 가장 간단한 형태의 residual-connection |
오른쪽: 1 x 1 conv 를 추가해서 연산량을 줄인 모델_ |
ResNet의 Idea는 gradient vanishing 문제를 이전 Layer의 결과를 더해줌으로써 해결하자이다. Inception 모델 역시 이를 사용했다.
 Residual을 사용하여 학습 수렴속도상승
Residual을 사용하여 학습 수렴속도상승
정리
하나의 Convoltion X
다양한 크기 Convolution -> Concate O
Inception 모델이 주안점을 두고 설계한 포인트는 다음과 같다.
Convolution을 할 때 하나의 큰 kernel 을 사용할게 아니라 다양한 크기를 이어붙이기Residual사용Convolution연산에Asymmetric Convolution Factorizing사용
Xception
파라미터 개수를 더 줄여보자. 극단적으로.
- 영향을 받은 핵심 포인트
- VGG16 : 깊게, 더 깊게
- Inception Family: Conv 를 할 때 몇개의 branch 로 factorize 해서 진행
- Depthwise Separable Convolution
- 네트워크의 사이즈와 연산량을 줄이기 위한 연구(채널별로 conv 를 진행한 후 feature map에 대해서 conv 를 진행)
- 변화된 핵심 포인트
- Modified Depthwise Separable Convolution
Depthwise Separable Convolution
Depthwise(깊이 별로 == 채널 별로) Separable(나누어서) convolution
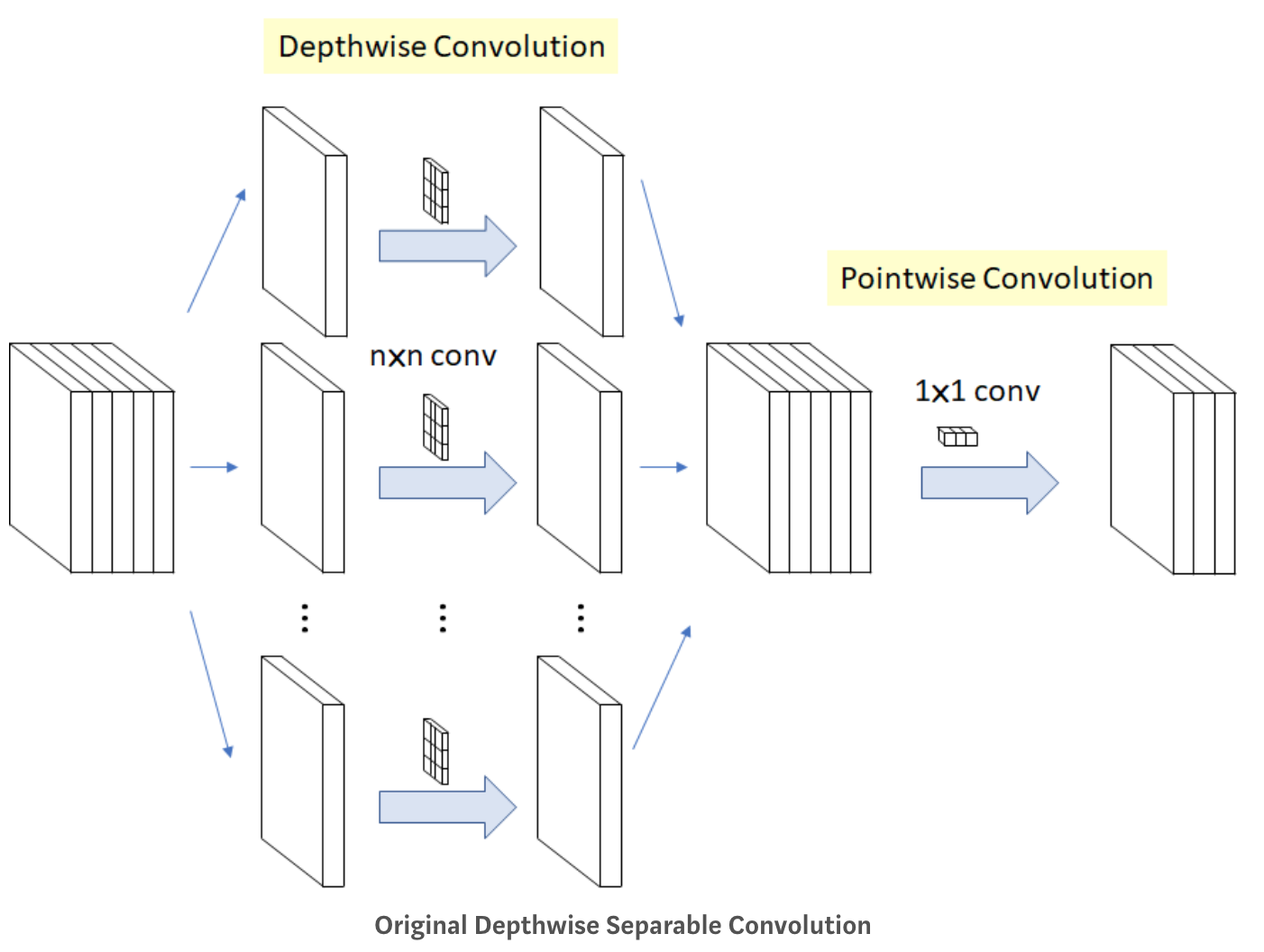 Depthwise Separable Convolution
Depthwise Separable Convolution
Channel-wise nxn spatial convolution
위에 그림에서와 같이 인풋으로 5개의 채널이 들어오면 5개의 n x n convolution 을 따로 진행해서 합친다.
Pointwise Convolution
원래 우리가 알고있는 1x1 convolution입니다. 채널의 개수를 줄이기 위한 방법으로 사용된다.
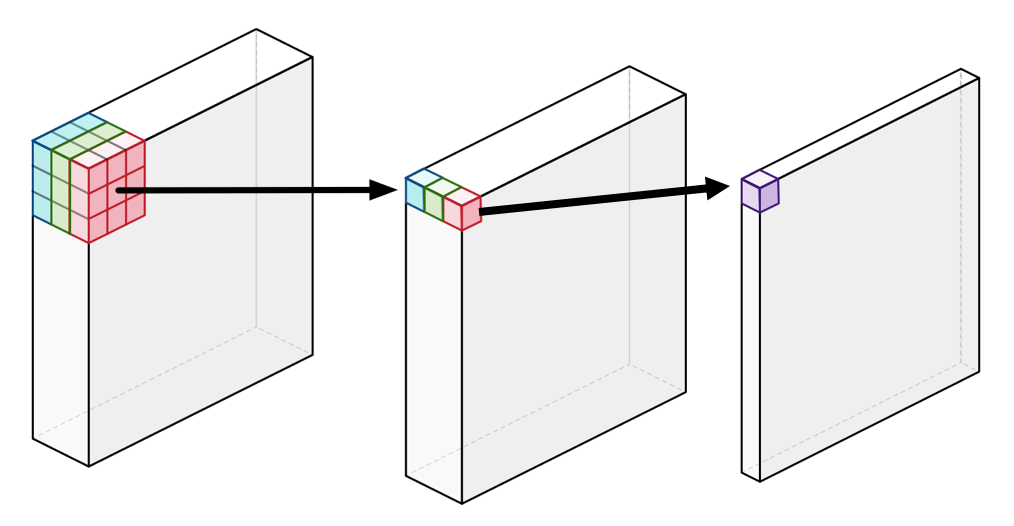 Depthwise Separable Convolution process
Depthwise Separable Convolution process
위와 같이 256 x 256 x 3 의 인풋이 있을 때, 1) 256 x 256 x 1 을 3번 진행해서 concat을 한다. 2) pointwise convolution을 이용해서 채널의 개수를 1개로 줄인다! (단순하게 weighted sum 을 계산하는 것) 위와 같은 과정으로 Convolution 을 하면 약 9배 정도 빠르다고 한다.
계산량 확인
- 동일한 정보
- 특징 맵의 크기: F x F
- 입력 채널 수: N
- 커널 크기: K x K
- 출력 채널 수: M
위와 같은 상황에서 어떻게 계산량이 달라지는지 보자.
- 일반 convolution 의 계산량
- 계산량 F x F x N x K x K x M
- Parameter 수: K x K x N x M
- Point-wise 의 계산량
- Channel-Wise
- Parameter 수: N x M Depthwise: 특징맵 채널마다 각각 공간 방향의 convolution 을 한다
- 채널방향으로 수행하지 않기 때문에 일반 convolution 1회의 cost -> K x K
- 계산량: F x F x N x K x K
- Parameter 수: K x K x N
- Pointwise
- 같은 크기의 아웃풋을 만들어 낸다
- 특징 맵의 차원을 늘리거나 줄일 때 사용된다
- K = 1 으로 만든 것.
- 계산량: F x F x N x M
- Channel-Wise
결론: 계산량: FxFxNxKxKxM –> FxFxNxM + FxFxNxKxK로 감소
즉, 소요시간은 1/M + 1/K^2 이다. 보통 M » K^2 이므로 계산량은 1/9정도가 된다.
Modified Depthwise Separable Convolution
Depthwise Separable Convolution와 큰 부분이 달라지진 않는다. 간략하게 차이점만 이해해보자.
- 연산의 순서
- 원래는
depthwise를 진행하고,pointwise를 했는데, 이제는pointwise->depthwise로 바꿈
- 원래는
- Non-Linearity 의 유무
Inception모델의 경우, 첫 연산 후에 non-linearity (ReLU)가 있지만, Xception은 중간에 ReLU non-linearity 를 적용하지 않음.
Residual connection이 거의 모든 Layer 에 있다.- 없애고 실험해봤더니 있을때의 정확도가 훨씬 높았음.
- residual connection 이 굉장히 중요한 요소임
구조
구조 자체는 굉장히 간단해서 밑에 있는 사진을 보면 쉽게 이해가 간다.
 Overall Architecture
Overall Architecture
Entry, Middle, Exit의 3개 구조로 나뉜다.
- Entry Flow
- 인풋: 229 x 229 x 3
- 모든 convolutional layer 다음에는 batch normalization 을 사용한다
- 2번 normal convolution (3x3) -> 필터의 갯수: 32 -> 64
- Residual Network 가 합쳐진 Inception Module 3번
- Middle Flow
- 반복되는 단순한 모델: 필터의 개수와 width/height 는 바뀌지 않음
- ReLU -> Separable Conv -> Separable Conv 8번 반복
- Exit Flow
- filter의 개수를 늘린다음 -> Maxpooling -> 2번 separable convolution -> Global Average Pooling -> Optional Fully-Connected -> Logistic Regression