이 포스팅은 Computer Vision 시리즈 17 편 중 13 번째 글 입니다.
목차
개요
앞서 배운 Dilated Convolution(atrous convolution) 을 적극적으로 활용할 것을 제안하여 segmentation 을 해결하자는 논문이다.
발전 방향
- DeepLab V1 :
Atrous convolution을 처음 적용 - DeepLab V2 :
multi-scale context를 적용하기 위한Atrous Spatial Pyramid Pooling (ASPP)기법을 제안 - DeepLab V3 : 기존
ResNet구조에Atrous Convolution을 활용해 좀 더 Dense한 feature map을 얻는 방법을 제안 - DeepLab V3+ :
Depthwise Separable Convolution과Atrous Convolution을 결합한Atrous Separable Convolution의 활용을 제안
DeepLab V3+ 논문은 2018년 8월 경, 구글에서 작성된 논문이다.
Semantic Segmentation을 해결하기 위한 방법론은 여러가지가 존재한다. 그 중 DeepLab 시리즈는 여러 segmentation model 중 성능이 상위권에 많이 포진되어 있는 model들이다. 그 중에서도 가장 성능이 높으며 DeepLab 시리즈 중 가장 최근에 나온 DeepLab V3+에 대해 살펴보자. 해당 논문은 앞서 작성된 V1, V2, V3에 대한 내용을 계승하고 있다. 따라서 V3+를 리뷰하며 이 내용들을 모두 알아보자 한다.
사용 개념
Atrous Convolution
 Atrous Convolution
Atrous Convolution
Atrous에서 trous는 구멍(hole)을 의미함으로써, Atrous Convolution은 기존 Convolution과 다르게 필터 내부에 빈 공간을 둔 채 작동하게 된다.
위 그림에서 얼마나 빈 공간을 둘지 결정하는 파라미터값 r(rate의 약자)이 1인 경우, 기존 Convolution과 동일하고 r이 커질수록 빈 공간이 넓어지게 되는 것이다.
이러한 Atrous Convolution을 활용함으로써 얻을 수 있는 이점은 기존 convolution과 동일한 양의 파라미터와 계산량을 유지하면서도, field of view(한 픽셀이 볼 수 있는 영역)를 크게 가져갈 수 있게 된다는 것이다.
보통 Semantic Segmentation에서 높은 성능을 내기 위해서는 CNN의 마지막에 존재하는 한 픽셀이 입력값에서 어느 크기의 영역에서 커버할 수 있는지를 결정하는 receptive field 크기가 중요하게 작용한다.
즉, 여러 convolution과 pooling 과정에서 디테일한 정보가 줄어들고 특성이 점점 추상화되는 것을 어느정도 방지할 수 있기 때문에 DeepLab series에서는 이를 적극적으로 활용하려 노력한다.
Atrous Spatial Pyramid Pooling(ASPP)
 Atrous Spatial Pyramid Pooling
Atrous Spatial Pyramid Pooling
Semantic segmentaion의 성능을 높이기 위한 방법 중 하나로, spatial pyramid pooling 기법이 자주 활용되고 있는 추세이다.
DeepLab V2에서 feature map으로부터 rate가 다른 Atrous Convolution을 병렬로 적용한 뒤, 이를 다시 합쳐주는 ASPP기법을 활용할 것을 제안했었다. 최근 발표된 PSPNet에서도 Atrous Convolution을 활용하진 않았지만 이와 비슷한 Pyramid Pooling 기법을 활용하였다.
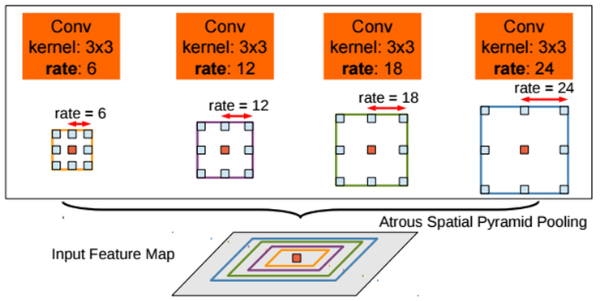 Atrous Spatial Pyramid Pooling
Atrous Spatial Pyramid Pooling
이러한 이러한 방법들은 multi-scale context를 모델 구조로 구현하여 보다 정확한 Semantic Segmentation을 수행할 수 있도록 도우며, DeepLab V3부터는 ASPP를 기본 모듈로 계속 사용하고 있다.
Depthwise separable convolution
 일반적으로 사용되는 Convolution 모습
일반적으로 사용되는 Convolution 모습
위 그림은 일반적으로 사용되는 Convolution을 나타낸 사진이다. 입력 이미지가 883(HWC)이고, Convolution 필터 크기가 33(FF)이라고 할 때, 필터 한개가 가지는 파라미터 개수는 333(FFC)=27이 된다. 만약 필터가 4개라면, 해당 Convolution의 총 파라미터 수는 3*3*3*4(F*F*C*N)만큼 지니게 된다.
 Depthwise Convolution 모습
Depthwise Convolution 모습
Convolution 연산에서 Channel 축을 필터가 한 번에 연산하는 대신에 위 그림과 같이 입력 영상의 Channel 축을 모두 분리시킨 뒤, Channel 축 길이를 항상 1로 가지는 여러 개의 Convolution 필터로 대체시킨 연산을 Depthwise Convolution이라고 한다.
 Depthwise Separable Convolution 모습
Depthwise Separable Convolution 모습
위의 Depthwise Convolution으로 나온 결과에 대해 11C 크기의 Convolution 필터를 적용한 것을 Depthwise Separable Convolution이라 한다.
이처럼 복잡한 연산을 수행하는 이유는 기존 Convolution과 유사한 성능을 보이면서도 사용하는 파라미터 수와 연산량을 획기적으로 줄일 수 있기 때문이다.
예를 들어, 입력값이 883이고 16개의 3*3 Convolution 필터를 적용할 때 사용되는 파라미터 개수는
- Convolution : 33316(HWCN) = 432
- Depth Separable Convolution : 333(HWC1) + 316(113*N) = 27+48 = 75
임을 확인 할 수 있다.
Depthwise Separable Convolution은 기존 Convolution 필터가 Sepatial Dimension과 Channel Dimension을 동시에 처리하던 것을 따로 분리시켜 각각 처리한다고 볼 수 있다. 이 과정에서, 여러 개의 필터가 Spatial Dimension 처리에 필요한 파라미터를 하나로 공유함으로써 파라미터의 수를 더 줄일 수 있게 되는 것이다. 이 부분은 Dilated convolution에서 배운 내용과 상등하다.
두 축을 분리시켜 연산을 수행하더라도 최종 결과값은 결국 두 가지 축 모두를 처리한 결과값을 얻을 수 있으므로, 기존 convolution filter가 수행하던 역할을 충분히 대체할 수 있게 된다.
Encoder-Decoder
DeepLab V3+는 위에서 설명한 모듈을 Encoder-Decoder로 구조화시켰다.
 U-net구조
U-net구조
동작
미리 보기
 DeepLab V3 구조
DeepLab V3 구조
DeepLab V3는 기본적으로 ResNet을 Backbone으로 사용하였으며 구조는 다음과 같다.
- Encoder : ResNet with Atrous Convolution
- ASPP
- Decoder : Bilinear Upsampling
 DeepLab V3+ 구조
DeepLab V3+ 구조
여기서 DeepLab V3+가 변경된 부분은 다음과 같다.
- Encoder : ResNet with Atrous Convolution를 Xception으로 변경
- ASP을 ASSPP (Atrous Separable Spatial Pyramid Pooling)로 변경
- Decoder : Bilinear Upsampling을 Simplified U-Net style decoder으로 변경
세부 설명
 DeepLab V3+ 세부 구조
DeepLab V3+ 세부 구조
Encoder with Atrous Convolution
DCNN에서 Atrous Convolution을 통해 임의의 resolution으로 feature map을 뽑아낼 수 있도록 한다.
여기서 Output Stride의 개념이 쓰이는데 “input image의 resolution과 최종 output의 비”로 생각하면 된다. 즉, 최종 feature map이 input image에 비해 32배 줄어들었다면 output stride는 32가 되는 것이다.
Semantic Segmentation에서는 더욱 디테일한 정보를 얻어내기 위해 마지막 부분의 Layer을 1개 혹은 2개를 삭제 후 Atrous Convolution해줌으로써 Output Stride를 16 혹은 8로 줄인다.
그리고 아래 사진과 같이 다양한 크기의 물체 정보를 잡아내기 위해 다양한 rate의 Atrous Convolution을 사용하는 ASPP(Atrous Spatial Pyramid Pooling)을 사용한다.
 Atrous Spatial Pyramid Pooling
Atrous Spatial Pyramid Pooling
Decoder
이전의 DeepLab V3에서는 Decoder 부분을 단순히 bilinear upsampling해주었으나, V3+에서는 Encoder의 최종 Output에 1*1 Convolution을 하여 Channel을 줄이고 bilinear upsampling 해준 후 Concat하는 과정이 추가되었다.
하지만 이러한 과정을 거치더라도 bilinear interpolation만으론 정확하게 객체의 픽셀 단위까지 위치를 정교히 segmentation하는게 불가능하다. 저자들은 뒷부분에 CRF(Conditional Random Field)를 이용하여 post-processing(후처리)을 수행하도록 했다. 이에 대한 자세한 설명은 밑에 하도록 하겠다.
Backbone
DeepLab V3+에서는 Xception을 backbone으로 사용하지만 MSRA의 Aligned Xception과 다른 3가지 변화를 주었다.
 왼쪽 : 원래의 Xception 모델, 오른쪽 : 논문에서 사용된 변형 Xception 모델
왼쪽 : 원래의 Xception 모델, 오른쪽 : 논문에서 사용된 변형 Xception 모델
- 빠른 연산과 메모리 효율을 위해
Entry Flow Structure를 수정하지 않았다. Atrous Separable Convolution을 적용하기 위해 모든 Pooling Opearation을Depthwise Separable Convolution으로 대체하였다.- 각각의
3*3 Depthwise Convolution이후에 추가적으로Batch-norm과ReLU활성화 함수를 추가해주었다.
Fully Connected CRF
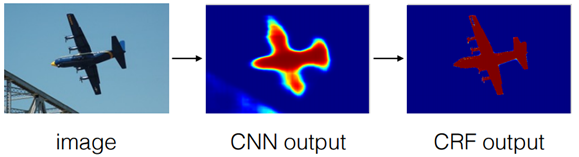 CRF 사용 후 선명도의 개선
CRF 사용 후 선명도의 개선
일반적으로 1/8크기 해상도를 갖는 DCNN 결과를 bilinear interpolation을 통해 원영상 크기로 확대하면 아래처럼 해상도가 떨어지는 문제가 있다. DeepLab 구조에서는 이 문제 해결을 위해 CRF(Conditional Random Field)를 사용하는 후처리를 이용해 성능을 향상시켰다.
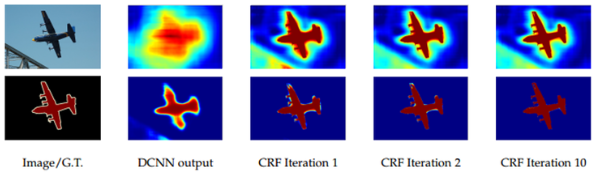 CRF 반복 횟수에 따른 결과 양상
CRF 반복 횟수에 따른 결과 양상
왜 CRF(Conditional Random Field)가 필요한가?
Classification과 같이 object-centric한 경우 가능한 높은 수준의 공간적인 불변성(spatial invariance)를 얻기 위해 여러 단계의 conv+pooling을 통해 영상 속에 존재하며 변화에 영향을 크게 받지 않은 강인한 특징을 추출해야하며, 이로인해 detail한 정보보단 global한 정보에 집중하게 된다.
반면 semantic segmenation은 픽셀 단위의 조밀한 예측이 필요해 classification 네트워크 기반으로 segmentation 망을 구상하게 된다면 계속 feature map의 크기가 줄어들게되는 특성상 detail한 정보들을 잃게 된다.
이 문제에 대한 해결책으로 FCN에선 skip connection을 사용하였고, dilated conv나 DeepLab에서는 마지막에 오는 pooling layer 2개를 없애고 dilated/atrous conv를 사용했다. 후에 작성할 Mask RCNN에서는 Roi align을 사용해서 이를 해결하고자 했다.
하지만 이러한 방법을 사용하더라도 분명히 한계는 존재하기에 DeepLab에서는 atrous conv에 그치지 않고 CRF를 후처리 과정으로 사용하여 픽셀 단위 예측의 정확도를 더 높일 수 있게 되었다.
개념
이전 노드(pixel)간의 관계(조건부 확률 같은)를 기반으로 현재 노드의 값을 추론한다.
일반적으로 좁은 범위(short-range)의 CRF는 segmentation을 수행한 뒤 생기는 segmentation noise를 없애는 용도로 많이 사용된다. 하지만 앞서 살펴본 것처럼 DCNN에서는 여러 단계 conv+pooling을 거치며 feature map의 크기가 작아지게 되고 이를 upsampling을 통해 원 영상 크기로 확대하기에 이미 충분히 smoothen되어있는 상태이며, 여기에 기존처럼 short-range CRF를 적용하면 결과가 더 나빠지게 된다.
Noise 성분도 같이 upsampling 되므로 세분화된 segmentation 결과를 얻기 어렵다. 이에 대한 해결책으로 Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials (Philipp Karahenbuhl)라는 논문이 발표되었으며, 해당 논문에선 기존에 사용되던 short-range CRF대신 전체 픽셀을 모두 연결한 (fully connected) CRF 방법을 개발해 놀라운 성능 향상을 얻어내었고 이 후 많은 사람들이 fully connected CRF를 후처리에서 사용하게 된다.
기존에 사용되던 short-range CRF는 아래 그림처럼 local connection 정보만을 사용한다. 이렇게 되면 detail 정보가 누락되게 된다.
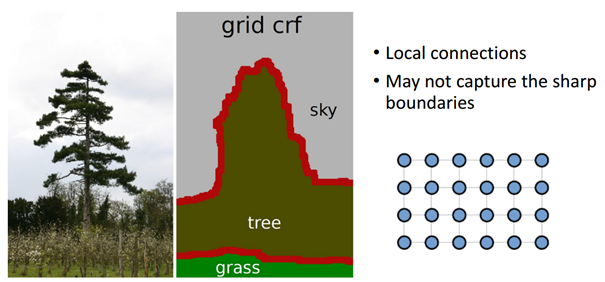 short range CRF 적용
short range CRF 적용
반면 fully connected CRF를 사용하면 아래처럼 detail 정보들이 살아있는 결과를 얻을 수 있다. 물론 모든 노드(pixel)을 연결하여 처리하기 때문에 굉장히 오랜 시간이 걸린다는 것을 알 수 있다.
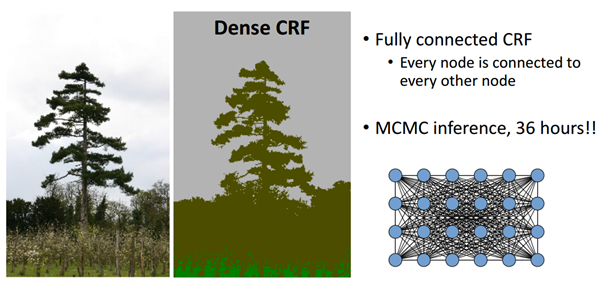 Fully connected CRF 적용
Fully connected CRF 적용
위처럼 MCMC(Markov Chain Monte Carlo) 방식을 사용할 경우 좋은 결과가 나오지만 연산량이 많다는 단점이 있어 적용이 불가했다. 하지만 Philipp Karahenbuhl의 논문에서 이를 0.2초만에 효과적으로 연산가능하게 했다.
Philipp Karahenbuhl는 일명 mean field approximation 방법을 적용해 message passing을 사용한 iteration 방법을 적용하여 효과적으로 빠른 fully connected CRF를 수행 가능하도록 했다.
여기서 mean field approximation이란 물리학이나 확률이론에서 많이 사용되는 방법으로, 복잡한 모델을 설명하기 위해 더 간단한 모델을 선택하는 방식을 의미한다. 수많은 변수들로 이루어진 복잡한 관계를 갖는 상황에서 특정 변수와 다른 변수들의 관계의 평균을 취하게 되면, 평균으로부터 변화(fluctuation)를 해석하는데도 용이하고, 평균으로 단순화/근사화된 모델을 사용하면 전체를 조망하기에 좋다.
수식


 Conditional Random Field
Conditional Random Field
CRF의 수식을 보면 unary term과 pairwise term으로 구성됨. 아래의 식에서 x는 각 픽셀의 위치에 해당하는 픽셀의 label이며, i와 j는 픽셀의 위치좌표를 나타낸다. Unary term은 CNN 연산을통해 얻어질 수 있으며, 픽셀간의 detail한 예측에서 pairwise term이 중요한 역할을 한다. Pairwise term에서는 마치 bi-lateral filter에서 그러듯이 픽셀값의 유사도와 위치적인 유사도를 함께 고려한다.(필터에 대해서는 [Learn opencv by examples] 6. Gaussian 필터, Bilateral 필터, Median 필터를 읽어보자.)
 Conditional Random Field
Conditional Random Field
위 CRF 식을 보면, 2개의 가우시안 커널로 구성된 것을 볼 수 있으며 표준편차 를 통해 scale을 조절 할 수 있다. 첫 번째 가우시안 커널은 비슷한 컬러를 갖는 픽셀들에 대해 비슷한 label이 붙을 수 있도록 하며, 두 번째 가우시안 커널은 원래 픽셀의 근접도에 따라 smooth 수준을 결정한다. 위 식에서 $p_i, p_j$는 픽셀의 위치(position)를 나타내며 $I_i, I_j$는 픽셀의 컬러값(intensity)이다.
이것을 고속처리하기 위해 Philipp Krahenbuhl 방식을 사용하게 되면 feature space에서는 Gaussian convolution으로 표현 할 수 있게되어 고속 연산이 가능해진다. (아 이부분은 도저히..)
CRF가 적용된 동작 방식
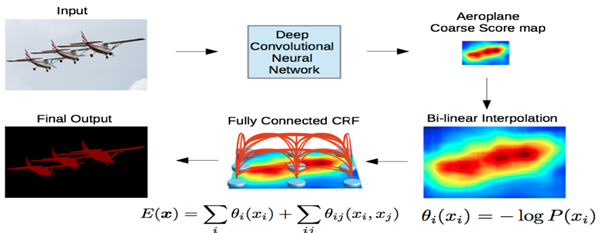 CRF까지 적용된 동작 방식
CRF까지 적용된 동작 방식
- DCNN을 통해 1/8 크기의
coarse score-map을 구한다. - 이것을
bilinear interpolation을 통해 원영상 크기로 확대시킴. Bilinear interpolation을 통해 얻어진 결과는 각 픽셀 위치에서의 label에 대한 확률이 되며 이것은CRF의unary term에 해당함.- 최종적으로 모든 픽셀 위치에서 p
airwise term까지 고려한CRF후보정 작업을 해주면 최종적인 출력 결과를 얻을 수 있음
결과
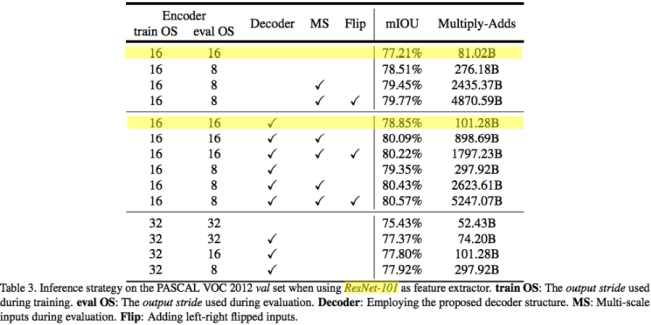
Encoder : Xception
 decoder 변경 후 결과
decoder 변경 후 결과
Encoder를 Xception으로 교체 후 실험하였을 때는 약 2% 가량의 성능 향상을 가져왔다.
ASPP 부분과 Decoder 부분에 사용되는 Convolution들을 모두 Separable Convolution으로 대체할 경우 성능은 기존 Convolution을 사용할 때와 거의 비슷하였지만, 모델이 사용하는 연산량 자체가 획기적으로 줄어들었음을 확인 할 수 있었다.
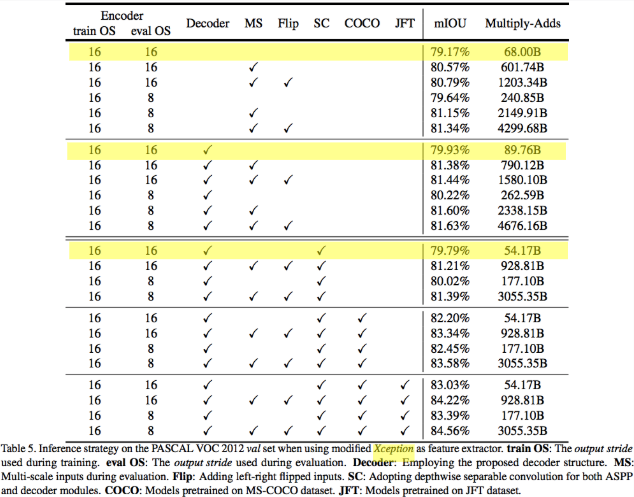
Decoder : U-Net 사용
 decoder 변경 후 결과
decoder 변경 후 결과
다양한 파라미터와 세팅에 대해서 실험을 진행하였는데, 우선 ResNet-101 구조를 Encoder로 사용하였을 때, 성능을 측정한 것이다. Decoder 부분을 bilinear upsampling 대신, 단순화된 U-Net 구조로 변경할 경우 기존 대비 mIOU 1.64% 향상이 있음을 확인 할 수 있다.
 Pascal VOC 2012 validation set에서의 visualization 결과
Pascal VOC 2012 validation set에서의 visualization 결과
위 Visualization 결과를 보면 상당히 안정적이고 정확하게 각각의 픽셀에 대해 클래스를 예측하고 있음을 확인할 수 있다. Xception 기반의 encoder로 양질의 high level semantic 정보를 가지는 feature를 추출할 수 있고, ASPP 모듈을 통해 각 픽셀이 여러 스케일의 context 정보를 취해 보다 정확한 추론이 가능하며, U-Net 구조의 decoder를 통해 각 물체에 해당하는 정교한 boundary를 그려낼 수 있기에 위와 같은 visualization 결과를 얻어낼 수 있다고 해석해 볼 수 있다.
Reference
DeepLabv3+ 원리 Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials