이 포스팅은 Computer Vision 시리즈 17 편 중 14 번째 글 입니다.
목차
개요
 structure of mask RCNN
structure of mask RCNN
- Facebok AI Research (FAIR), Kaiming He, 24 Jan 2018
- Marr Prize at ICCV 2017
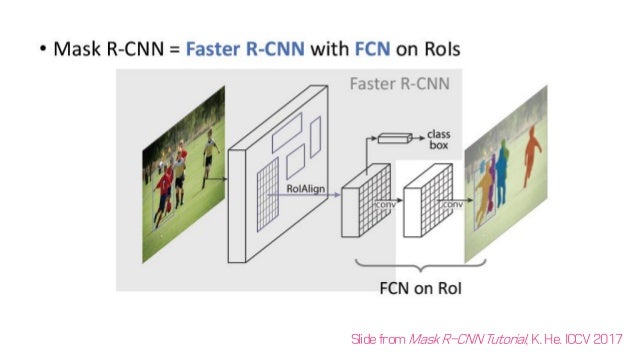
object instance segmentation을 위한 프레임 워크이다. 기존의 semantic segmentation을 넘어서 각각의 instance도 구분이 가능한 구조를 만들었다. 학습이 쉽고 Faster RCNN에 조금의 overhead만 추가하여 5fps의 빠르기로 실행된다. COCO 데이터셋에서 instance segmentation, bbox object detection, person keypoint detection 에서 가장 높은 결과를 보였다.
핵심 아이디어
Faster R-CNN에서 detect한 각각의 box에 mask를 씌워주자!
instance segmentation은 두 가지 과제를 합친 것이다.
- object detection
- bbox를 이용하여 object를 분류하고, 위치를 찾는 것.
- semantic segmentation
- object instance는 구별하지 않지만, 정해진 카테고리별로 각각의 pixel을 분류하는 것
이전의 Segmentation에서 중요한 논문인 FCN에서는 총 3가지를 고려하였다.
- pixel 단위의 classification
- 그렇기 때문에 pixel 단위 softmax 값 추출이 필요
- multi instance를 고려해야 함
하지만 mask RCNN은 Faster RCNN을 그대로 가져다가 쓰기 때문에, 이 문제가 다소 변경된다.
pixel 단위의 classification-> 이미 bounding box로 구분을 해줌그렇기 때문에 pixel 단위 softmax 값 추출이 필요-> bounding box 안에서 물체 인지 아닌지만 구분해주면 됨(Sigmoid)multi instance를 고려해야 함-> 이미 multi instance로 bounding box를 쳐줌
 class, box 외에 mask FCN만 추가한다.
class, box 외에 mask FCN만 추가한다.
결과적으로, 이 문제에서 해야할 일은 masking을 수행하는 것이다. 그래서 논문이름도 Mask RCNN이다.
Equivariance
input에서의 변화가 output의 변화에 영향을 준다.
 Invariance vs. Equivariance
Invariance vs. Equivariance
classification 문제에서는 label을 도출하는 문제이기 때문에 Invariance 하다. 하지만 segmentation 문제 같은 경우에는 output이 원래 이미지 사이즈와 같아야 하기 때문에 이 문제는 Equivariance로 해결 해야한다. 이 때, 저자들은 convolution은 translation-equivariance 하기 때문에 이 네트워크를 사용했다.
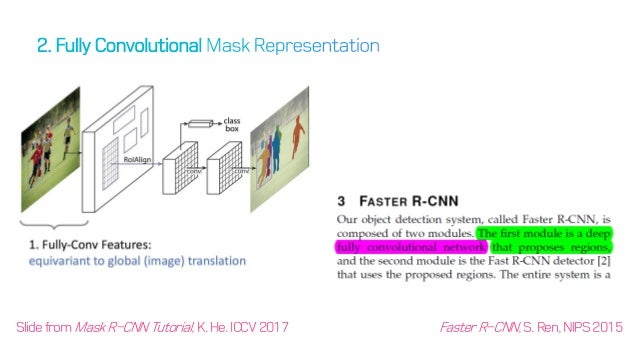
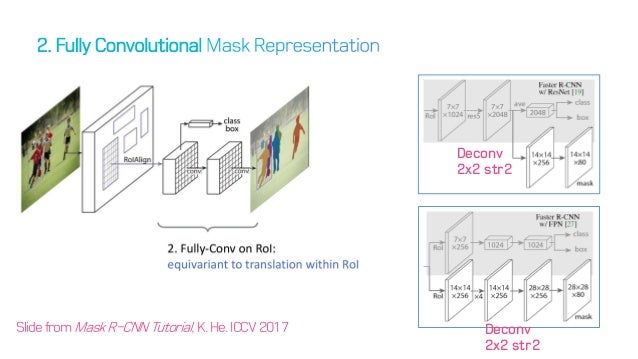 Fully convolutional network 사용
Fully convolutional network 사용
mask RCNN의 구조를 담당하는 Faster RCNN은 Fully conv net을 사용하고 있다. 여기서 mask RCNN은 뒤의 mask head부분 역시 FCN을 사용하여 제작하였다.
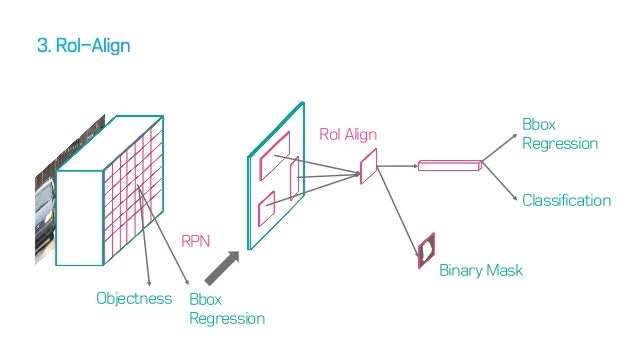
RoI Align
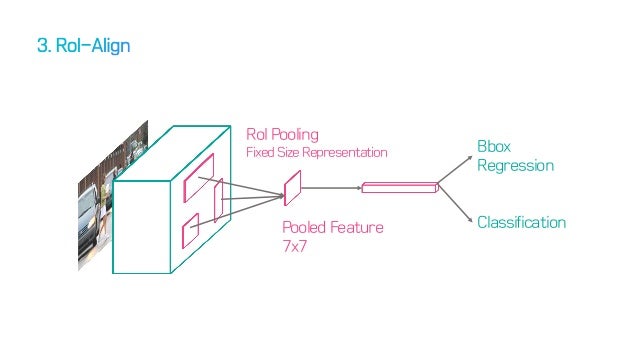 기존의 Faster RCNN의 구조
기존의 Faster RCNN의 구조
기존에 Faster RCNN에서는 feature map을 뽑아낸 뒤, Region proposal Network를 사용하여 이를 제시하였다. 그 방법은 RoI pooling이었다. 하지만 segmentation은 detection 문제와 다르게 단지 box를 치는 문제가 아니다. 좀더 정확한 위치정보를 담은 상태의 feature map이 필요하다.
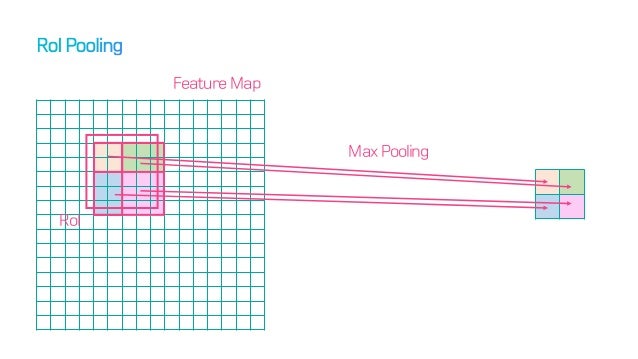 RoI pooling은 proposal의 위치를 반올림한다.
RoI pooling은 proposal의 위치를 반올림한다.
기존의 RoI Pooling을 생각해보면, 4개의 좌표 변환 값을 regression하고, 이를 기반으로 예상 좌표를 얻어낸 뒤(실수) 이를 반올림하여 정수단위인 pixel의 위치를 제안한다. 하지만, 소수점을 반올림한 좌표를 가지고 Pooling을 해주면 input image의 원본 위치 정보가 왜곡된다. classfication에는 이런 문제가 심각하지 않지만, pixel-by-pixel로 detection을 진행해야 하는 segmentation 에서는 문제가 발생한다.
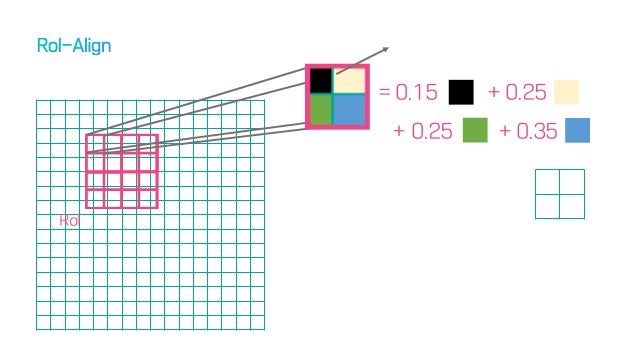 RoI Align
RoI Align
이 문제를 해결하기 위해 저자들은 다음과 같은 방법을 통해 이를 해결한다.
- 제안된 proposal을 들고온다.
- Roi pooling에서 4등분 했던 것처럼 일단 자른다.
- 그 안에서 추가적으로 4등분을 한다. (subcell)
- 이렇게 발생한 격자내에 들어오는 픽셀의 면적을 기준으로 가중평균한다.
- 발생한 값을 기준으로 pooling한다.
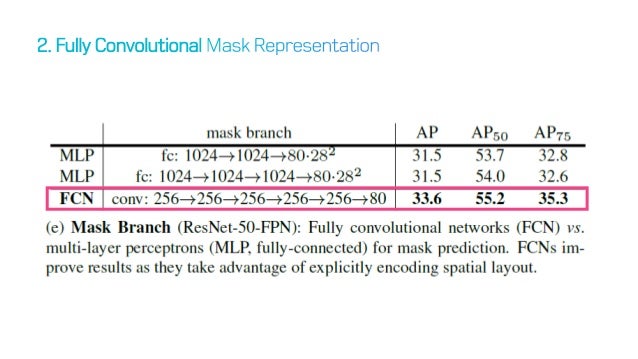
이 방법은 Mask Accuracy에서 큰 향상을 보였다.
Mask RCNN architecture
Mask R-CNN은 여러 가지 아키텍쳐를 합친 네트워크인데, 크게 두 가지로 나뉜다.
- Convolutional backbone architecture
- 이미지에서 feature extraction
- Network head
- bounding-box 인식(classification & regression), mask 예측
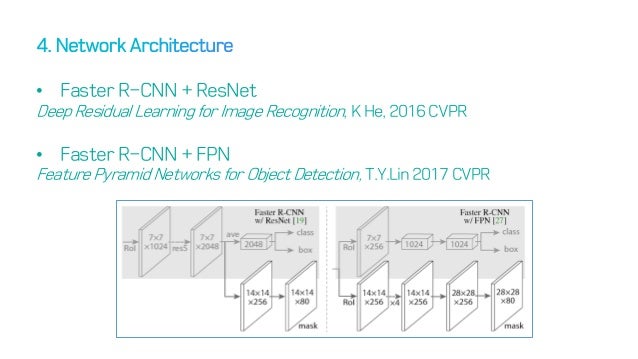 Head Architecture
Head Architecture
ResNet Backbone
논문에서는 ResNet 과 ResNeXt networks 를 depth 50 or 101 layers에 대해 평가했다. 원래 Faster R-CNN은 ResNet을 사용하는데, 4번째 스테이지의 마지막 Conv layer(이하 C4)에서 features를 뽑아낸다. 이 경우, 이 backbone을 사용한다면 우리는 ResNet-50-C4 와 같이 부를 것이다. ResNet-50-C4가 일반적으로 사용된다.
ResNet-FPN Backbone
FPN은 Feature Pyramid Network로, top-down architecture를 사용한다. FPN backbone을 사용하는 Faster R-CNN은 피쳐 피라미드의 서로 다른 레벨로부터 RoI features를 뽑아내지만, 나머지는 vanilla ResNet과 같다. Mask R-CNN에서 피쳐 추출을 위해 ResNet-FPN backbone을 이용하는 것은 정확도와 속도 면에서 엄청난 향상을 보였다. Feature Pyramid Network는 추후 글에서 작성하도록 하겠다.
Loss function (decoupling)
\[L = L_{cls} + L_{box} + L_{mask}\]- $L_{cls}$ : Softmax Cross Entropy (loss of classification)
- $L_{box}$ : bbox regression
- $L_{mask}$ : Binary Cross Entropy
위의 아이디어를 그대로 가져와서, 결과적으로 masking만 하는 loss 함수를 정의하여 사용한다. 그림으로 이해해 보자.
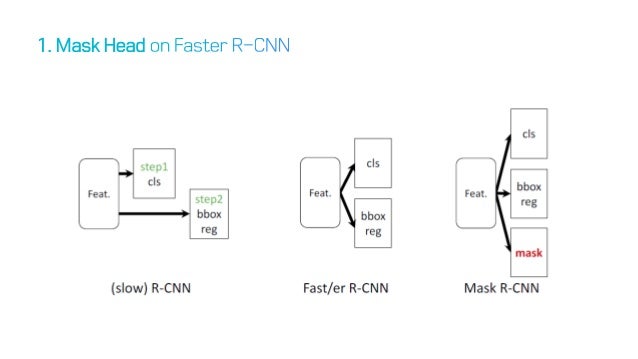 이전 방법들과의 비교
이전 방법들과의 비교
그림을 보게되면, 단순히 masking을 하는 구조를 추가하고, 이를 반영하는 방식으로 진행된다.
 mask Head의 loss update 방법
mask Head의 loss update 방법
update 방법은 상당히 단순한데, 일단 전체 mask loss는 모든 클래스(사람, 말 등)에서 차이가 나는 mask의 정도로 정의가 된다. 하지만 해당 사진에서 bounding box는 하나만 box 처리가 되어 있다. 기존의 faster RCNN에서 bounding box를 예측할 때는 하나의 box만 처리하기 때문이다. 이런 상황에서 mask에 대한 업데이트는 모든 사물에 대해서 업데이트를 할 수 없게 된다. 그래서 이렇게 해당 사진의 class가 정해질 경우, 해당 class에 해당하는 mask만을 선택하고 이를 업데이트 해준다. 즉, 말이 정답 class인 경우, 이 class에 해당하는 mask만 학습된다.
결과적으로 이렇게 학습되는 mask branch는 어떠한 class인지 상관 없이 물체의 masking만 따는 것을 배우게 된다.
 test senario
test senario
이렇게 학습된 mask branch는 실제로 여러개의 물체에 대한 mask라고 예측할 것이다. 하지만 이 녀석은 어떠한 물체인지 분간하지 못하는데, 이부분에 있어서 classification의 결과를 넣어주어, 하나의 masking을 제안한다. 즉 mask prediction에서는 단지 이 pixel이 mask인지, 아닌지 만을 구분(sigmoid 사용)하도록 하여 성능의 향상을 보였다. 이러한 방법을 Mask prediction 과 class prediction 을 decouple 했다고 한다.
 decouple을 시도했을 때 올라간 정확도
decouple을 시도했을 때 올라간 정확도