이 포스팅은 Kaggle::Titanic 시리즈 10 편 중 5 번째 글 입니다.
목차
Kaggle에 있는 Titanic Prediction 문제의 데이터를 정제한다.
데이터 정제
이 단계에서 우리는 데이터를 정제한다.
방법론
- 잘못된 값과 이상치를 수정한다.
- 결측치를 채워넣는다.
- 분석에 필요한 새로운 feature를 생성한다.
- 계산을 위해 변수의 data format을 변경한다.
이 방법에 대해 하나씩 자세히 알아보자.
- Correcting
- 데이터를 다시 보면서 이상하거나 납득하기 어려운 데이터를 확인한다. 하지만 수정은 조심해야 한다. 잘못된 판단으로 원래 데이터를 수정할 경우 올바르지 않은 결과가 나올 수 있기 때문이다. 따라서 EDA를 수행한 후 어느정도의 지식을 얻은 후에 수행하기로 한다.
-
Completing
- age, cabin, embarked field에는 결측치나 Null이 많다. Null은 상당히 위험한데, 알고리즘이 받아들일 수 없는 경우가 있기 때문이다. 예를 들어 결정 트리는 null을 받아들일 수 있지만, 다른 알고리즘은 그렇지 않다. 따라서 이 값을 변경하는 것은 매우 중요하다. 이 부분에 있어서는 두가지 접근이 사용된다.
- 값을 지운다.
- 추천하지는 않는 방법이다. 특히 많은 부분의 record(row)가 빈 값으로 생각되지 않는다면 수행하면 안된다.
- 합리적인 값으로 대체한다.
- 지우기 보다는 이것이 나은 방법이다.
- 좋은 방법론으로는, 결측치를 평균, 중앙값, 평균+편차, 최빈값등을 사용하는 것이다.
- 중급의 방법론은 특정 기준을 사용하여 채워넣는 것이다. 클래스별 나이, 요금에 따른 적재 항구와 같은 것들이 그것이다.
- 복잡한 방법론이 있지만, 최종 모델을 선정하기 전에, 추가한 feature로 인한 복잡도가 가치가 있는지를 확인해야 한다. 이번에는 age의 빈값은 중앙값으로, cabin은 삭제하며, embark는 최빈값으로 대체된다. 추후 모델에서 이러한 결정을 수정하며 모델을 개선할 수 있다.
- 값을 지운다.
- age, cabin, embarked field에는 결측치나 Null이 많다. Null은 상당히 위험한데, 알고리즘이 받아들일 수 없는 경우가 있기 때문이다. 예를 들어 결정 트리는 null을 받아들일 수 있지만, 다른 알고리즘은 그렇지 않다. 따라서 이 값을 변경하는 것은 매우 중요하다. 이 부분에 있어서는 두가지 접근이 사용된다.
- Creating
- Feature engineering은 이미 존재하는 feature를 가지고 새로운 feature를 제작하여 결과에 새로운 영향력을 주는지를 판단하는 과정이다. 예를 들어, 이번 문제에서는 title(master)이 생존에 있어 중요했는지를 판단할 수 있다.
- Converting
- 마지막으로 데이터 포맷을 변경하는 것이다. 날짜나 통화와 같은 데이터 형식일 경우 이것을 변경해줘야 한다. 이번 문제에서는 이산, 연속, 범주형 등의 데이터 형식이 있다. 이런 부분을 계산이 가능하도록 dummy변수화 해준다.
print('Train columns with null values:\n', data1.isnull().sum())
print("-"*10)
print('Test/Validation columns with null values:\n', data_val.isnull().sum())
print("-"*10)
data_raw.describe(include = 'all') # 통계적으로 한번에 결과를 볼 수 있다.
Train columns with null values:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
----------
Test/Validation columns with null values:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
----------
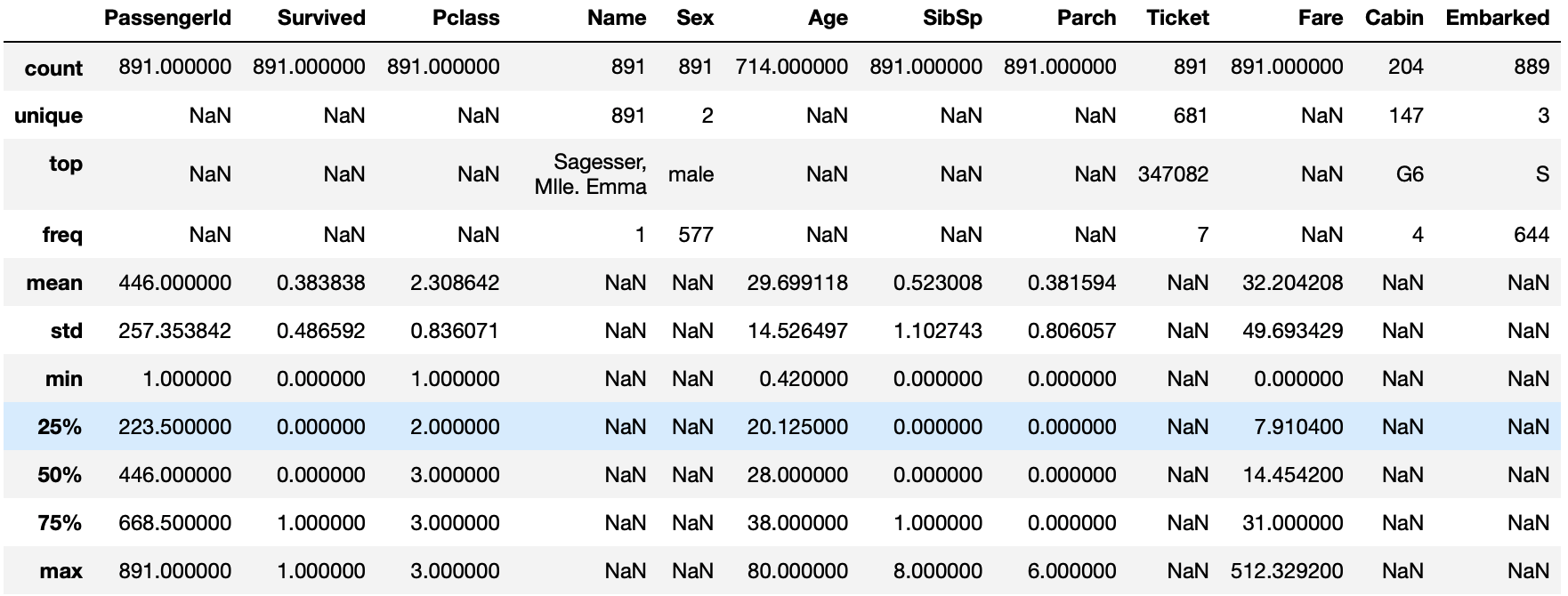
정제 시작
이제 어떻게 할 지 알았으니 실제로 시작해보자.
Developer Documentation:
pandas.DataFrame
pandas.DataFrame.info
pandas.DataFrame.describe
Indexing and Selecting Data
pandas.isnull
pandas.DataFrame.sum
pandas.DataFrame.mode
pandas.DataFrame.copy
pandas.DataFrame.fillna
pandas.DataFrame.drop
pandas.Series.value_counts
pandas.DataFrame.loc
Complete (채우기)
# 결측치를 지운다.
for dataset in data_cleaner:
# age를 중앙값으로 채운다.
dataset['Age'].fillna(dataset['Age'].median(), inplace = True)
# 최빈값으로 대체
dataset['Embarked'].fillna(dataset['Embarked'].mode()[0], inplace = True)
# 중앙값으로 대체
dataset['Fare'].fillna(dataset['Fare'].median(), inplace = True)
# 사용하지 않을 feature를 제거해준다.
drop_column = ['PassengerId','Cabin', 'Ticket']
data1.drop(drop_column, axis=1, inplace = True)
print(data1.isnull().sum())
print("-"*10)
print(data_val.isnull().sum())
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
----------
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64
Create (생성하기) - feature engineering
for dataset in data_cleaner:
# Family Size 추가
dataset['FamilySize'] = dataset ['SibSp'] + dataset['Parch'] + 1 # 나까지 추가
dataset['IsAlone'] = 1 # 혼자라고 초기화
dataset['IsAlone'].loc[dataset['FamilySize'] > 1] = 0 # 가족 크기가 1보다 클 경우 혼자가 아님
dataset['Title'] = dataset['Name'].str.split(", ", expand=True)[1].str.split(".", expand=True)[0] # expand가 True이면, 하나의 컬럼을 두개로 나눌 수 있다.
# df[['split_1', 'split_2']] = df['email'].str.split('@', expand=True)
# 실수 값을 범주형으로 바꾼 feature를 추가한다.
dataset['FareBin'] = pd.qcut(dataset['Fare'], 4) # 같은 갯수에 해당하는 범위로 쪼갠다. 리턴은 해당 범주
dataset['AgeBin'] = pd.cut(dataset['Age'].astype(int), 5) # 등간격 5개로 쪼갠다. 리턴은 해당 범주
# cleanup rare title names
print(data1['Title'].value_counts()) # 만든 title의 개수를 생각해보자.
stat_min = 10 # 작다는 것이 임의적이나, 만연하게 사용하는 작은 수는 10이다. http://nicholasjjackson.com/2012/03/08/sample-size-is-10-a-magic-number/
title_names = (data1['Title'].value_counts() < stat_min) # 10보다 count가 작은 친구들을 true로 만든다.
#apply and lambda functions are quick and dirty code to find and replace with fewer lines of code: https://community.modeanalytics.com/python/tutorial/pandas-groupby-and-python-lambda-functions/
data1['Title'] = data1['Title'].apply(lambda x: 'Misc' if title_names.loc[x] == True else x) # 잡다한 것들 Misc
print(data1['Title'].value_counts())
print("-"*10)
#preview data again
data1.info()
data_val.info()
data1.sample(10)
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Col 2
Major 2
Mlle 2
Lady 1
Sir 1
the Countess 1
Jonkheer 1
Don 1
Capt 1
Ms 1
Mme 1
Name: Title, dtype: int64
Mr 517
Miss 182
Mrs 125
Master 40
Misc 27
Name: Title, dtype: int64
----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 14 columns):
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null float64
Embarked 891 non-null object
FamilySize 891 non-null int64
IsAlone 891 non-null int64
Title 891 non-null object
FareBin 891 non-null category
AgeBin 891 non-null category
dtypes: category(2), float64(2), int64(6), object(4)
memory usage: 85.5+ KB
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 16 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 418 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 418 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
FamilySize 418 non-null int64
IsAlone 418 non-null int64
Title 418 non-null object
FareBin 418 non-null category
AgeBin 418 non-null category
dtypes: category(2), float64(2), int64(6), object(6)
memory usage: 46.8+ KB
Continuous variable bins; qcut vs cut
Fare Bins/Buckets using qcut or frequency bins
Age Bins/Buckets using cut or value bins
qcut에서 사용하는 minimum sample size
pandas 문자열 다루기
Convert (변환하기) - 수치화
수학적 계산을 위해 범주형 데이터를 더미 변수화 한다. 범주형 데이터를 encoding하는 다양한 방법이 있다. sklearn과 pandas 함수를 사용하겠다.
이 단계에서 우리는 사용한 독립 변수 x(independent/features/explanatory/predictor/etc.)와 종속 변수 y(dependent/target/outcome/response/etc.)를 정의한다.
Developer Documentation
Categorical Encoding
Sklearn LabelEncoder
Sklearn OneHotEncoder
Pandas Categorical dtype
pandas.get_dummies
# code categorical data
label = LabelEncoder()
for dataset in data_cleaner:
dataset['Sex_Code'] = label.fit_transform(dataset['Sex'])
dataset['Embarked_Code'] = label.fit_transform(dataset['Embarked'])
dataset['Title_Code'] = label.fit_transform(dataset['Title'])
dataset['AgeBin_Code'] = label.fit_transform(dataset['AgeBin'])
dataset['FareBin_Code'] = label.fit_transform(dataset['FareBin'])
#define y variable aka target/outcome
Target = ['Survived']
# raw 데이터에서 사용할 변수를 선택한다.
data1_x = ['Sex','Pclass', 'Embarked', 'Title','SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone'] # pretty name/values for charts
data1_x_calc = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code','SibSp', 'Parch', 'Age', 'Fare'] #coded for algorithm calculation
data1_xy = Target + data1_x
print('Original X Y: ', data1_xy, '\n')
# 숫자로 바꾼 데이터, 구간인 데이터를 숫자로 바꾼다. (양자화)
data1_x_bin = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code', 'FamilySize', 'AgeBin_Code', 'FareBin_Code']
data1_xy_bin = Target + data1_x_bin
print('Bin X Y: ', data1_xy_bin, '\n')
# 모델의 입력으로 사용할 dummy data를 만든다.
data1_dummy = pd.get_dummies(data1[data1_x])
data1_x_dummy = data1_dummy.columns.tolist()
data1_xy_dummy = Target + data1_x_dummy
print('Dummy X Y: ', data1_xy_dummy, '\n')
data1_dummy.head()
Original X Y: ['Survived', 'Sex', 'Pclass', 'Embarked', 'Title', 'SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone']
Bin X Y: ['Survived', 'Sex_Code', 'Pclass', 'Embarked_Code', 'Title_Code', 'FamilySize', 'AgeBin_Code', 'FareBin_Code']
Dummy X Y: ['Survived', 'Pclass', 'SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone', 'Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S', 'Title_Master', 'Title_Misc', 'Title_Miss', 'Title_Mr', 'Title_Mrs']

Double Check
print('Train columns with null values: \n', data1.isnull().sum())
print("-"*10)
print (data1.info())
print("-"*10)
print('Test/Validation columns with null values: \n', data_val.isnull().sum())
print("-"*10)
print (data_val.info())
print("-"*10)
data_raw.describe(include = 'all')
Train columns with null values:
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
FamilySize 0
IsAlone 0
Title 0
FareBin 0
AgeBin 0
Sex_Code 0
Embarked_Code 0
Title_Code 0
AgeBin_Code 0
FareBin_Code 0
dtype: int64
----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 19 columns):
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 891 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Fare 891 non-null float64
Embarked 891 non-null object
FamilySize 891 non-null int64
IsAlone 891 non-null int64
Title 891 non-null object
FareBin 891 non-null category
AgeBin 891 non-null category
Sex_Code 891 non-null int64
Embarked_Code 891 non-null int64
Title_Code 891 non-null int64
AgeBin_Code 891 non-null int64
FareBin_Code 891 non-null int64
dtypes: category(2), float64(2), int64(11), object(4)
memory usage: 120.3+ KB
None
----------
Test/Validation columns with null values:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
FamilySize 0
IsAlone 0
Title 0
FareBin 0
AgeBin 0
Sex_Code 0
Embarked_Code 0
Title_Code 0
AgeBin_Code 0
FareBin_Code 0
dtype: int64
----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 21 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 418 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 418 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
FamilySize 418 non-null int64
IsAlone 418 non-null int64
Title 418 non-null object
FareBin 418 non-null category
AgeBin 418 non-null category
Sex_Code 418 non-null int64
Embarked_Code 418 non-null int64
Title_Code 418 non-null int64
AgeBin_Code 418 non-null int64
FareBin_Code 418 non-null int64
dtypes: category(2), float64(2), int64(11), object(6)
memory usage: 63.1+ KB
None
----------
data1과 data_val 모두에 구간 변수가 잘 추가되었다.
Training data와 Testing data를 나누자.
3.25 Split Training and Testing Data
우리가 가진 train데이터를 잘 나누어, 훈련한 모델의 성능을 확인해야 한다. 여기서 우리는 sklearn 함수를 통해 데이터를 75/25로 나눌 것이다. 이 부분은 overfit our model을 방지하기 위해 중요하다. sklearn’s train_test_split function을 사용하여 데이터를 나눌 것이다. 이 단계 이후에는 sklearn’s cross validation functions을 사용하여 훈련된 모델을 비교할 것이다.
#split train and test data with function defaults
#random_state -> seed or control random number generator: https://www.quora.com/What-is-seed-in-random-number-generation 랜덤 넘버를 주어서 원하는 랜덤을 정의할 수 있다.
train1_x, test1_x, train1_y, test1_y = model_selection.train_test_split(data1[data1_x_calc], data1[Target], random_state = 0)
train1_x_bin, test1_x_bin, train1_y_bin, test1_y_bin = model_selection.train_test_split(data1[data1_x_bin], data1[Target] , random_state = 0)
train1_x_dummy, test1_x_dummy, train1_y_dummy, test1_y_dummy = model_selection.train_test_split(data1_dummy[data1_x_dummy], data1[Target], random_state = 0)
print("Data1 Shape: {}".format(data1.shape))
print("Train1 Shape: {}".format(train1_x.shape))
print("Test1 Shape: {}".format(test1_x.shape))
train1_x_bin.head()
# train1_x.head()
# train1_x_dummy.head()
Data1 Shape: (891, 19)
Train1 Shape: (668, 8)
Test1 Shape: (223, 8)
이 부분을 통해서, data1에서 구간으로 나눈 feature에 대해 split하고, dummy화 된 data에 대해서도 이를 수행했다.