이 포스팅은 Kaggle::Titanic 시리즈 10 편 중 8 번째 글 입니다.
목차
Kaggle에 있는 Titanic Prediction 문제를 모델링한 결과를 바탕으로 모델을 평가한다.
모델 성능 평가
현재까지의 상황을 보면, baseline 코드로 82%의 정확도를 가지는 모델을 만들었다. 여기서 중요한 것은, 데이터 과학자가 사업적 측면을 생각하고 만든다는 것에 있다. 즉, 투자대비 성능(ROI)를 고민하는 것이 좋다. 연구하는 사람이 아니라면 지나친 성능확대는 시간 낭비일 뿐이기 때문이다.
기준 정확도 결정
동전 뒤집기를 생각해보자. 우리가 맞춰야 하는 것은 특정 상황에서 이 동전이 앞면이 나올지 뒷면이 나올지를 예측해야 한다. 그 예측값을 위해, 바람, 힘의 크기와 같은 변수들이 주어졌다고 하자. 그런데, 내가 만든 모델이 50%확률로 동전의 앞, 뒤를 맞춘다면, 이만큼 쓸모없는 모델도 없을 것이다. 왜냐하면, 이 정보는 그저 동전을 던지면서 발생하는 빈도수로도 예측이 가능한 결과이기 때문이다.
이번에는 타이타닉 문제에 적용해보자. 우리는 training data를 근간으로 1,502 / 2,224=67.5%(약 68%)의 확률로 생존, 사망을 알 수 있다. 그러므로 내가 만든 모델의 성능은 이보다는 높은 결과를 가져와야 의미있는 것이라 할 수 있다. 이러한 방법으로 내가 만든 모델의 최악의 성능 마지노선을 설정할 수 있다.
나만의 모델 만들기 (Handmade)
어떻게 모델을 만들 수 있는 지 배워보는 입장에서 적어본다.
Coin flip model
#coin flip model with random 1/survived 0/died
#iterate over dataFrame rows as (index, Series) pairs: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.iterrows.html
for index, row in data1.iterrows():
#random number generator: https://docs.python.org/2/library/random.html
if random.random() > .5: # Random float x, 0.0 <= x < 1.0
data1.set_value(index, 'Random_Predict', 1) #predict survived/1
else:
data1.set_value(index, 'Random_Predict', 0) #predict died/0
# coin flip 모델의 성능을 검증해보자. 옳게 맞추면 1, 아니면 0이다.
#the mean of the column will then equal the accuracy
data1['Random_Score'] = 0 #assume prediction wrong 초기화
data1.loc[(data1['Survived'] == data1['Random_Predict']), 'Random_Score'] = 1 #set to 1 for correct prediction
print('Coin Flip Model Accuracy: {:.2f}%'.format(data1['Random_Score'].mean()*100)) # 평균치를 구한다.
# 혹은 그냥 내장 함수를 사용하자.
#http://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html#sklearn.metrics.accuracy_score
print('Coin Flip Model Accuracy w/SciKit: {:.2f}%'.format(metrics.accuracy_score(data1['Survived'], data1['Random_Predict'])*100))
Coin Flip Model Accuracy: 47.14%
Coin Flip Model Accuracy w/SciKit: 47.14%
group화 후 판단하기
#group by or pivot table: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.groupby.html
pivot_female = data1[data1.Sex=='female'].groupby(['Sex','Pclass', 'Embarked','FareBin'])['Survived'].mean()
print('Survival Decision Tree w/Female Node: \n',pivot_female)
pivot_male = data1[data1.Sex=='male'].groupby(['Sex','Title'])['Survived'].mean()
print('\n\nSurvival Decision Tree w/Male Node: \n',pivot_male)
여자만 다양한 지표로 구분한 이유는 위의 EDA를 해보았을 때, 남자는 놀랍게도 class나, embarked에 따라 생존률이 다르지 않았다. 하지만 title이라는 변수는 유의미했다.
Survival Decision Tree w/Female Node:
Sex Pclass Embarked FareBin
female 1 C (14.454, 31.0] 0.666667
(31.0, 512.329] 1.000000
Q (31.0, 512.329] 1.000000
S (14.454, 31.0] 1.000000
(31.0, 512.329] 0.955556
2 C (7.91, 14.454] 1.000000
(14.454, 31.0] 1.000000
(31.0, 512.329] 1.000000
Q (7.91, 14.454] 1.000000
S (7.91, 14.454] 0.875000
(14.454, 31.0] 0.916667
(31.0, 512.329] 1.000000
3 C (-0.001, 7.91] 1.000000
(7.91, 14.454] 0.428571
(14.454, 31.0] 0.666667
Q (-0.001, 7.91] 0.750000
(7.91, 14.454] 0.500000
(14.454, 31.0] 0.714286
S (-0.001, 7.91] 0.533333
(7.91, 14.454] 0.448276
(14.454, 31.0] 0.357143
(31.0, 512.329] 0.125000
Name: Survived, dtype: float64
Survival Decision Tree w/Male Node:
Sex Title
male Master 0.575000
Misc 0.250000
Mr 0.156673
Name: Survived, dtype: float64
여기서 잘 관찰해 보면, 여자이면서 class가 3이며, S 항구에서 출항한 여성들의 요금 구간에 따라 생존율이 다른 것을 볼 수 있다. 이 부분은 tree 구조로 쪼개면 정확도가 상승할 것이다. 남자의 경우는 title에 따라 생존율이 극명하게 다르다.
내가 만드는 tree
#handmade data model using brain power (and Microsoft Excel Pivot Tables for quick calculations)
def mytree(df):
#initialize table to store predictions
Model = pd.DataFrame(data = {'Predict':[]})
male_title = ['Master'] #survived titles
for index, row in df.iterrows():
#Question 1: Were you on the Titanic; majority died 타이타닉에 있으면 일단 죽었다고 가정
Model.loc[index, 'Predict'] = 0
#Question 2: Are you female; majority survived : 여자는 살았다고 가정
if (df.loc[index, 'Sex'] == 'female'):
Model.loc[index, 'Predict'] = 1
#Question 3A Female - Class and Question 4 Embarked gain minimum information
#클래스에 따라 나누는 것은 큰 정보이득이 없다. (즉, 클래스에 따른 생존률의 차이가 없다. 정보이득이 없다. 고르게 분포되어 있어 분기를 만드는 것이 의미가 없다.)
#Question 5B Female - FareBin; set anything less than .5 in female node decision tree back to 0
# 여자이며 클래스가 3번, 출항 항구가 S 그리고 돈을 8보다 많이 낸 사람들은 생존했다. 아마 못사는 사람들이 돈을 더 많이 내지 않았을까..
if ((df.loc[index, 'Sex'] == 'female') &
(df.loc[index, 'Pclass'] == 3) &
(df.loc[index, 'Embarked'] == 'S') &
(df.loc[index, 'Fare'] > 8)
):
Model.loc[index, 'Predict'] = 0
#Question 3B Male: Title; set anything greater than .5 to 1 for majority survived
# master 지위를 가진 사람만 생존했다고 가정하자.그럼 남자중 57%는 생존했다고 할 수 있다.
if ((df.loc[index, 'Sex'] == 'male') &
(df.loc[index, 'Title'] in male_title)
):
Model.loc[index, 'Predict'] = 1
return Model
#model data
Tree_Predict = mytree(data1)
print('Decision Tree Model Accuracy/Precision Score: {:.2f}%\n'.format(metrics.accuracy_score(data1['Survived'], Tree_Predict)*100))
#Accuracy Summary Report with http://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html#sklearn.metrics.classification_report
#Where recall score = (true positives)/(true positive + false negative) w/1 being best:http://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html#sklearn.metrics.recall_score
#And F1 score = weighted average of precision and recall w/1 being best: http://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html#sklearn.metrics.f1_score
print(metrics.classification_report(data1['Survived'], Tree_Predict))
Decision Tree Model Accuracy/Precision Score: 82.04%
precision recall f1-score support
0 0.82 0.91 0.86 549
1 0.82 0.68 0.75 342
avg / total 0.82 0.82 0.82 891
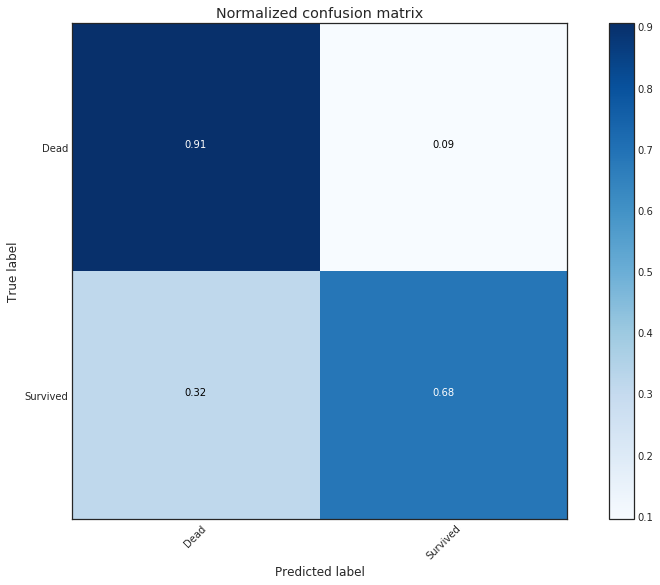
혼동 행렬(Confusion Matrix) 만들기
#Plot Accuracy Summary
#Credit: http://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] # 차원을 하나 늘려 세로로 만들어주는 개념
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# Compute confusion matrix
cnf_matrix = metrics.confusion_matrix(data1['Survived'], Tree_Predict)
np.set_printoptions(precision=2)
class_names = ['Dead', 'Survived']
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names,
title='Confusion matrix, without normalization')
# Plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names, normalize=True,
title='Normalized confusion matrix')
Confusion matrix, without normalization
[[497 52]
[108 234]]
Normalized confusion matrix
[[ 0.91 0.09]
[ 0.32 0.68]]